

En la era del Big Data y la transformación digital, muchas empresas han invertido en un Data Lake (un repositorio centralizado que almacena, procesa y protege los datos) con su respectivo equipo detrás.
Se conoce como arquitectura tradicional de Data Lake monolítico, donde están todos los datos de la empresa centralizados en un solo Data Lake. Esto no es un problema en empresas que no tienen muchos dominios o que no consumen tantos dominios de datos como producen. Pero en empresas que sí lo hacen supone un cuello de botella, ya que, normalmente, un solo equipo de datos no da abasto para conocer tantos aspectos del negocio y, por ende, el dato solicitado por el negocio no se trata a la velocidad deseada.
Con el problema en la mesa, el mercado necesitaba una nueva solución orientada a estas empresas que tienen tantos dominios, donde cada uno de los dominios necesita su propio conjunto de datos y en algún caso consumir conjuntos de datos de otros dominios. Y la posible solución a estas empresas surgió con el concepto de Data Mesh, teorizada por Zhamak Dehghani.
¿Qué es el Data Mesh?
El Data Mesh es una transformación organizativa que intenta cambiar el mundo del dato monolítico a una plataforma descentralizada que promueve la ubicuidad del dato en la empresa, aprovechando un diseño de propiedad y distribución de servicios como muchas otras arquitecturas de software con un diseño guiado por el dominio (DDD).
Para lograr los conceptos mencionados, una plataforma Data Mesh tiene que encarnar los siguientes 4 principios.
- Propiedad de la especialización. Este primer principio indica que cada dominio que vaya a consumir datos tiene que asumir la responsabilidad de sus datos, trasladando así la propiedad de los datos de un equipo céntrico a un equipo especializado en su dominio.
- Datos como producto. El segundo principio habla de proyectar los datos generados por cada uno de los equipos especializados en sus dominios como si fuera un producto. Esto significa que cada dominio ha de generar datos de una calidad acordada con el resto de dominios aparte de consumirlos.
- Plataforma de auto servicio del dato. Para el tercer principio la teoría es que cada dominio entregue funcionalidades dominio-específico como herramientas y sistemas para construir, ejecutar, mantener y catalogar los productos para todos los demás dominios, por lo que al final cada dominio puede crear, consumir y encontrar dichos productos.
- Gobernanza asociada. El último de los principales principios indica que, mediante la gobernanza del dato y la infraestructura, se llegue a la interoperabilidad de todos los productos generados. Esto implica que el ecosistema que se vaya a crear se adhiera a unas reglas organizacionales y regulaciones de la industria.
Snowflake como infraestructura de Data Mesh
El principal objetivo de Snowflake es conectar organizaciones y equipos de datos a los datos más relevantes en el momento oportuno, sin complejidades ni silos. Sus características son el rendimiento a escala, la facilidad de uso y la compartición del dato y, colaboraciones gobernadas, las cuales hacen de Snowflake una capa de infraestructura de datos para Data Mesh casi perfecto.
La principal ventaja es que cuenta con Snowgrid, una plataforma para distribuir datos entre los diferentes dominios, permitiendo acceso instantáneo a datos actualizados. La plataforma también incluye controles de gobernanza y políticas que van a la par que el dato que se comparte, permitiendo un acceso seguro y regulado entre los dominios. También se van la complejidad de que en una capa de Data Mesh, al terminar el producto, se tienen que montar los flujos para que el resto de dominios pueda acceder a ellos, copiando los datos o definiendo diferentes ETLs para acceder al producto, mientras que en Snowgrid el acceso a estos productos es directo y sin necesidad de construir estos flujos, mediante compartición segura de datos.
Otra ventaja de trabajar con Snowflake como la infraestructura de datos de un Data Mesh es por Snowflake Data Marketplace, el cual permite enriquecer los datos de un producto, si es necesario, con otros productos ya acabados y actualizados.
Y, por último, la ventaja de que Snowflake tiene un motor que permite ejecutar una variedad de lenguajes y tecnologías diferentes sin tener que sacrificar en velocidad o tener que implementar diferentes infraestructuras, ya que se pueden ejecutar tanto comandos SQL como una variedad de lenguajes de programación o una mezcla de ambos. Este motor tiene una escalabilidad elástica y la posibilidad de dividir los recursos a usar en diferentes clústeres sin impactar a otros dominios.
Estableciendo modelos Data Mesh en Snowflake
Una vez introducido el concepto y la compatibilidad, vayamos directo al grano con las estructuras que podemos usar como una base para empezar a trabajar tratando de implementar los conceptos de Data Mesh. Hay que tener en cuenta que no es sólo una transformación tecnológica, sino una transformación organizativa, en la que se incluyen aspectos no técnicos. Además, los modelos que mostraremos no son una guía definitiva para implementar correctamente Data Mesh, sino unas bases para empezar a conocerlo, ya que adoptar Data Mesh dependerá de la necesidad de cada empresa.
Modelo «Database per domain»
Se refiere a un modelo donde se usaría una sola cuenta Snowflake donde cada dominio consistiría en una combinación de base de datos con su clúster de cómputo. Cada dominio podría tener una o varias bases de datos para diferentes entornos de trabajo.
Para que este modelo funcione correctamente, es necesario que haya una capa de gobernanza de datos central y otra de gobernanza de datos por dominio, para que el acceso a los datos sea seguro.
El modelo puede abordarse de dos formas:
- Cada dominio tiene varios esquemas en su base de datos, teniendo que definir uno de ellos como producto para compartir con el resto de dominios, no necesita de catálogo de datos ya que se puede compartir mediante Data Marketplace de Snowflake
- Cada dominio tiene un esquema en una base de datos conjunta, donde publicará una vista de sus productos, necesita de un catálogo de datos externo para que el producto sea visible al resto de dominios.
Ventajas
- Facilidad de acceso a los productos mediante la implementación de permisos de bases de datos.
- Facilidad de administración de la red, seguridad y gobernanza ya que es centralizado.
- Es fácil de proteger ante desastres mediante el uso de la herramienta “Replication” de Snowflake.
Desventajas
- Necesita definir una convención de nomenclatura ya que todos los objetos de los diferentes productos recaen en una sola cuenta.
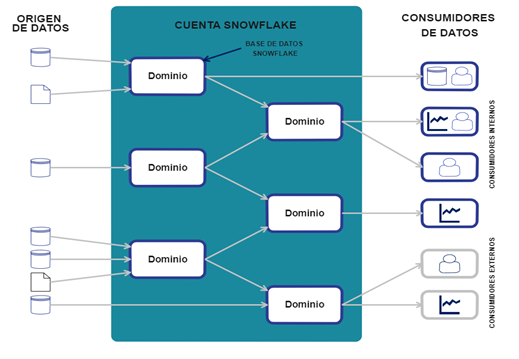
Modelo «Account per domain»
Se refiere al uso de una cuenta de Snowflake por cada dominio que tengamos. Esto permite una fácil implementación de Data Mesh para organizaciones que trabajen con diferentes regiones, o tengan una preferencia en la nube en la que se hospeda Snowflake. La estructura sería multi-cloud y multi-region.
Este modelo permite que estas organizaciones globales puedan gestionar los datos de una manera segura desde diferentes ubicaciones, ya que en muchos casos hay problemas con el cumplimiento de las regulaciones del dato. También permite las organizaciones que adquieran otros modelos o fusionen con otras organizaciones, puedan mantener la preferencia de cloud y evitar migrar todo.
La manera de compartir productos en este modelo es mediante las herramientas “Data sharing” y “Data Marketplace” de Snowflake.
Ventajas
- Permite conservar preferencias en regiones y cloud.
- La capa de seguridad y gestión de usuarios es gestionada por cada dominio.
- Nomenclaturas más sencillas no compartes nombres con el resto de dominios
Desventajas
Es necesario definir de antemano una capa de red, seguridad, gobernanza y uniformidad para que todos los dominios se puedan llegar a entender.
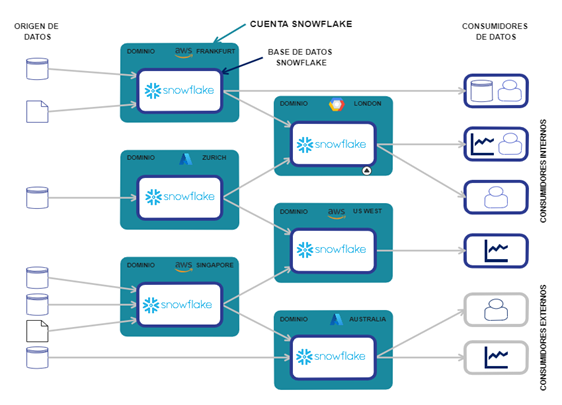
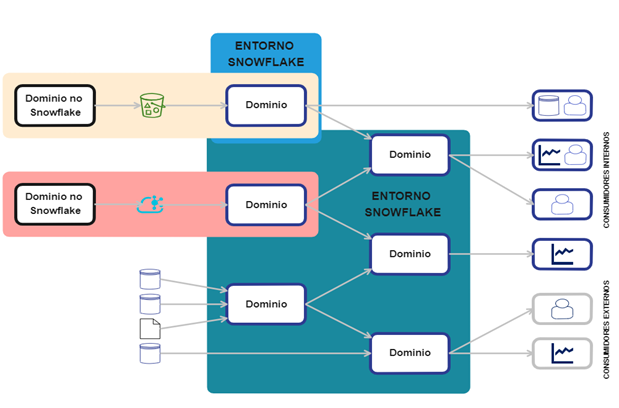
Modelo «Heterogeneous Architecture»
Se refiere a la integración de entornos que no son de Snowflake a los modelos anteriores. Es útil cuando se requiere de reusar diferentes repositorios o tecnologías que existen en diferentes partes de la organización.
La forma de actuar con este modelo sería que cada dominio generase con sus herramientas y tecnologías ya implementadas estos productos y se integrase en una o diferentes cuentas de Snowflake para que esta actúe como capa de desarrollo y capa de consistencia a la vez, siendo que la gobernanza, seguridad, interoperabilidad, etc., del Data Mesh sea gestionada por Snowflake.
Ventajas
- Posibilidad de reusar repositorios y datos que ya hubieran adoptado el modelo de producto.
Desventajas
- Coste y complejidad de mantenimiento de las diferentes herramientas y tecnologías usadas.
- Es más complicado asegurar consistencia en la gobernanza, seguridad, metadatos, interoperabilidad, rendimiento y habilidades necesarias.
Y finalizamos indicando que, aunque esto son unos modelos de ejemplo, cada organización tendrá que elegir cuál de ellas se adaptaría mejor a su negocio. Dicho esto, es algo complicado asegurar que usando estos modelos un Data Mesh vaya a tener éxito, ya que esta transformación organizativa no tiene mucho tiempo de vida y aún no hay un recorrido al cual se pueda seguir con garantía de éxito. Además, no es únicamente la selección del modelo, sino un cambio en el pensamiento monolítico e independiente que tenemos de una base de datos, y cómo interactúan las diferentes capas de negocio y desarrollo con el modelo escogido.
En Hiberus somos Service Partner Select de Snowflake y contamos con un equipo certificado en la plataforma que tiene una gran experiencia en el desarrollo de estrategias de datos. Podemos ayudarte a diseñar, migrar, implantar y sacar el máximo partido de las soluciones Snowflake más adecuadas para tu negocio. ¿Hablamos?

¿Quieres más información sobre nuestros servicios de Snowflake?
Contacta con nuestro equipo de Snowflake
