

El ISTQB (el esquema de certificación líder a nivel mundial en el campo de las pruebas de software) además de darnos los principios del testing básicos, también indica que los seres humanos cometen errores (equivocaciones), que producen defectos de software, que a su vez pueden dar lugar a fallos. Los defectos pueden encontrarse en la documentación, por ejemplo, en una especificación de requisitos, en un guion de prueba o en el código fuente. Si no se detectan los defectos durante el desarrollo del software, pueden dar lugar a software defectuosos más adelante en el ciclo de vida. Si se ejecuta un defecto en el código, el sistema puede fallar al hacer lo que debería hacer o hacer algo que no debería, provocando un fallo. Algunos defectos siempre darán lugar a un fallo, mientras que otros solo darán lugar a un fallo en circunstancias específicas, y algunos puede que nunca den lugar a un fallo.
Hay que tener en cuenta que los errores y defectos no son la única causa de los fallos, sino que estos también pueden deberse a condiciones ambientales, como cuando la radiación o el campo electromagnético provocan defectos en el firmware. Por esto es imprescindible implementar distintos tipos de pruebas de software.
Las razones fundamentales por las que se producen los fallos se identifican mediante el análisis de la causa raíz, que suele realizarse cuando se produce un fallo o se identifica un defecto. Se cree que pueden evitarse otros fallos o defectos similares o reducirse su frecuencia tratando la causa raíz, por ejemplo, eliminándola, por lo que es necesario hacer un análisis exhaustivo para determinarla.
Ciclo de vida de un defecto de software
Esta serie de estados por los que puede pasar un defecto en su ciclo de vida es una lista abierta de acuerdo con las necesidades del proyecto:
- En análisis: el analista comprueba la veracidad y reproducibilidad del defecto.
- En curso: el defecto está listo para ser corregido.
- En desarrollo: el equipo de desarrollo genera el código que solucionará el defecto. En algunos casos se añade un estado posterior a este en el que el código está pendiente de la aprobación para poder fusionarlo (merge).
- En pruebas: se pasa al equipo de testing para realizar las pruebas que verifiquen que se ha corregido el defecto.
- Validado QA: una vez que se ha verificado que el bug no se sigue reproduciendo, se pasa por este estado para posteriormente cerrarlo. En algunos casos el estado de validado QA corresponde al equipo de QA, mientras que el estado cerrado corresponde al stakeholder que comprueba que está corregido.
- No validado QA: cuando se sigue reproduciendo el defecto o aparece otro como consecuencia de la resolución de este, se retrocede en el issue y pasaría por este estado y, posteriormente, a En curso para su revisión.
- Cerrado: este estado se asigna al defecto cuando se considera que está corregido y subido el código a producción, o bien cuando no se considera un defecto. Podría, por ejemplo, pasar de En análisis a Cerrado directamente.
- Reabierto: este estado es útil cuando un defecto se ha cerrado por error.
Priorización y criticidad de defectos
Para la correcta gestión de los defectos se deben valorar dos aspectos muy importantes: la prioridad y la gravedad. Este segundo, la gravedad, se puede clasificar de la siguiente manera:
- Menor: se trata de un defecto que no afectaría al despliegue de la versión ya que no genera un fallo de funcionalidad. Por ejemplo: defectos visuales o de documentación.
- Medio: provoca algún comportamiento incorrecto, pero en funcionalidades poco importantes, por lo que el sistema sigue funcionando.
- Alto: es un defecto que no es bloqueante pero aun así se trata de una funcionalidad importante que no marcha como se espera, por lo que conviene solucionarlo cuanto antes para que la versión que se libere sea de calidad.
- Crítico: se trata de un defecto bloqueante, por lo que hay que solucionarlo cuanto antes para poder subir a desarrollo la versión final.
Para priorizar, existen métodos como el método Moscow, que nos puede ayudar en esta tarea. Esta técnica se usa en la gestión ágil de proyectos para el ajuste de prioridades que se basa en 4 categorías de priorización y que definen su acrónimo:
- Must have, funcionalidades que debe tener y que por lo tanto son imprescindibles en el proyecto,
- Should have, funcionalidades que debería tener y por tante no son tan críticas como las primeras aunque son muy importantes,
- Could have, aquellas que podría tener y que por tanto podrían aplazarse para un lanzamiento posterior del proyecto,
- Won’t have. Las que no se tendrán y por tanto se han rechazado y no es necesario tener en el proyecto.
Reporte de defectos de software
En herramientas de gestión de defectos, mucha de esta información se genera automáticamente: quién abrió el defecto o el histórico de cambios del defecto, por ejemplo. de todas maneras es información que puede ser útil por lo que en el caso de realizar el registro manualmente conviene tenerlos en cuenta.
Para la realización de un reporte de defecto es interesante recopilar los siguientes datos:
- Identificador único: diferencia un defecto de otro rápidamente.
- Título del defecto: debe ser autodescriptivo. Se propone seguir el siguiente esquema: [Entorno X] – Site – Funcionalidad – Breve descripción del defecto
- Fecha de localización del defecto: permite que llegado el caso se pueda saber que versión había desplegada en ese momento o si pudo afectar al funcionamiento algún otro agente externo.
- Entorno dónde se ha encontrado.
- Dispositivo y sistema operativo en el que se está probando.
- Objeto que se está probando: breve resumen de lo que se quiere probar.
- Versión en la que se está probando.
- Caso de prueba donde se localizó: es importante de cara a seguir una trazabilidad.
- Precondiciones o datos: aquí se incluirán datos como email y contraseña con los que se ha probado, productos o toda la información relevante y necesaria de cara a reproducir el defecto.
- Pasos para reproducir el defecto: detallar con precisión los pasos necesarios para repetir el defecto.
- Resultado esperado: explicar el resultado que se esperaba al ejecutar el test.
- Resultado obtenido: explicar el resultado que se ha obtenido al ejecutar el test.
- Información adicional: quizás sea necesario alguna aclaración o algún comentario que permita revisar otros casos de prueba o referencias a las capturas de pantalla y videos adjuntos.
- Archivos adjuntos: capturas de pantalla o videos donde se pueda ver como reproducir el defecto o el defecto en si, así como archivos con los logs o los ficheros que se cargan para poder reproducir el error.
- Criticidad: tal y como se comentaba en el apartado anterior, podría ser menor, medio, alto o crítico, es un campo importante de cara a la priorización de defectos.
- Prioridad: al igual que el de la criticidad, es importante de cara a la priorización de defectos.
- Estado del defecto: tal como se comentaba en el apartado de los estados por los que puede pasar un defecto aquí, según el proyecto, podría ser en curso, en análisis, en desarrollo..
- Sprint en el que se va a resolver el bug.
- Histórico de cambios.
- Etiquetas: se pueden crear etiquetas específicas que ayudarán a la hora de realizar filtros para poder clasificar los defectos.
- Componentes: se pueden especificar los posibles impactos en otros componentes o sistemas, si es del backend o del frontend.
- Tipo de tarea: en este caso sería bug, pero en caso de no haber un requerimiento claro podría valorarse el caso de que no fuese un defecto si no una nueva petición de funcionalidad por lo que se podría cambiar el tipo de tarea en este campo.
- Proyecto: especificar el proyecto al que afecta el defecto.
- Persona que reporta el defecto: para, en el caso de tener dudas, saber a quién preguntar.
- Persona que tiene asignado el defecto: es importante de cara a saber quien está trabajando en ese momento en el defecto y poder preguntar información al respecto.
- Enlaces a otras tareas, épicas, historias de usuario, requisitos o defectos relacionados o al repositorio de código.
- Versión en la que se corrige el defecto.
- Comentarios: Una buena práctica es añadir comentarios donde se indique cuales han sido las correciones que se han llevado a cabo, la causa del defecto, el momento del despliegue en los entornos de prueba o si a la hora de probar existían algunos bloqueos de agentes externos. Así como al comprobar que está resuelto, se debería dejar evidencia de la resolución del mismo y el entorno en el que se ha comprobado. Esto ayuda a los componentes del equipo a tener una referencia así como a tener constancia en un futuro de si se han producido defectos similares.
Herramientas para la gestión de defectos
Dentro del arsenal de un analista QA se encuentran algunas herramientas muy útiles a la hora de hacer la identificación y gestión de defectos de software. Estas son algunas de las más interesantes:
Jira
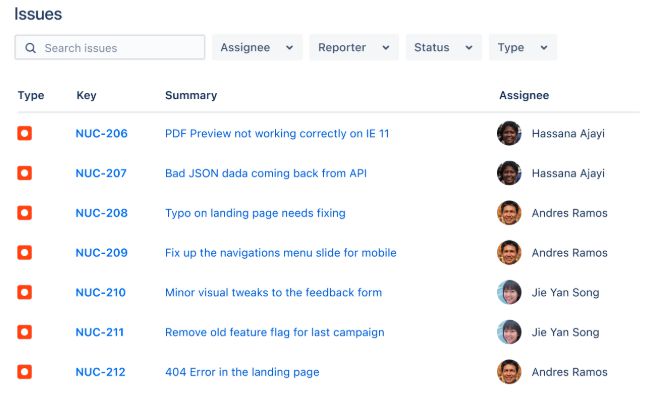
Se trata de una de las herramientas de gestión de proyectos más comunes, donde se pueden dar de alta issues de tipo bug como se puede ver en la siguiente imagen.
AzureDevops
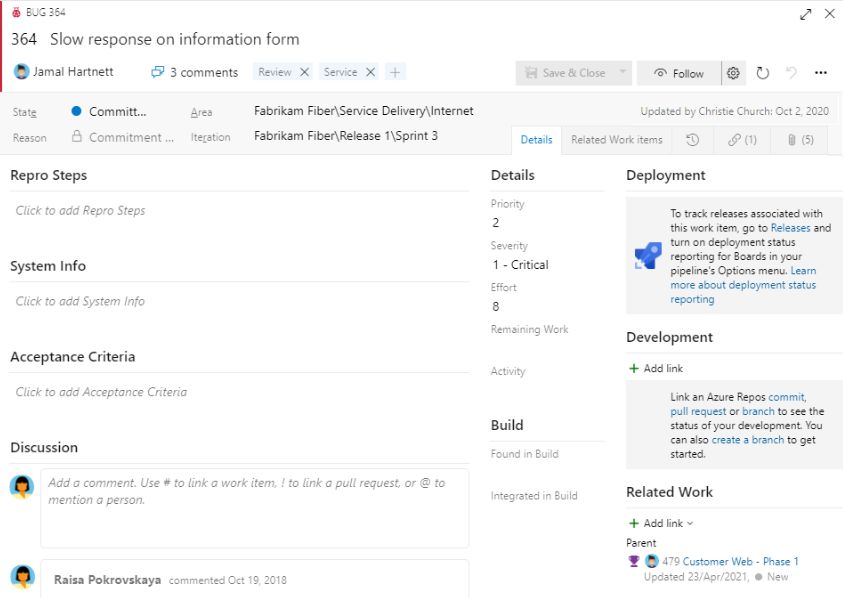
Otra herramienta en la que, al igual que Jira, se pueden reportar defectos asociados a casos de prueba o tareas:
Tricentis
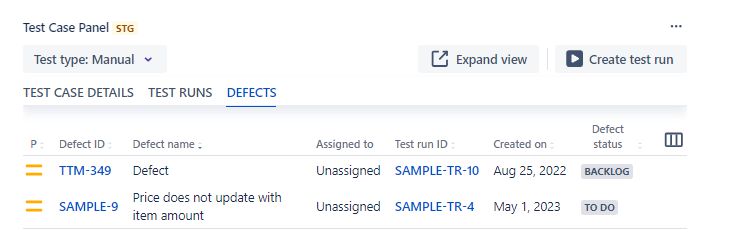
Nuestro partner tiene un sistema de gestión de defectos asociado a cada caso de prueba como se puede ver en la siguiente imagen:
En hiberus, contamos con un excelente equipo de especialistas QA expertos en asesorar sobre el uso de herramientas de testing. Además, somos Partners de Tricentis, líder mundial en pruebas continuas empresariales que ofrece una forma nueva y diferente de llevar a cabo las pruebas de software. Tricentis es una solución integral en el campo del aseguramiento de la calidad, ofreciendo innovación, flexibilidad y eficiencia, permitiendo a los equipos de desarrollo y QA no solo enfrentar los retos actuales, sino también prepararse para los desafíos futuros.

¿Quieres más información sobre Tricentis?
Contacta con nuestro equipo de expertos en QA y Testing
