

El desarrollo de DeepSeek y su modelo R1 ha marcado un hito en la inteligencia artificial al basarse en un método innovador: el aprendizaje por refuerzo puro. A diferencia de otros enfoques tradicionales que requieren grandes volúmenes de datos previamente etiquetados, DeepSeek ha logrado entrenar su modelo de manera autónoma, abriendo nuevas posibilidades para la creación de sistemas de IA más eficientes y menos dependientes de datos supervisados.
Qué es el aprendizaje por refuerzo
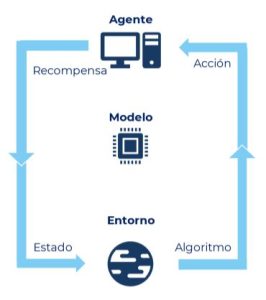
El aprendizaje por refuerzo es un tipo de inteligencia artificial que se inspira en la forma en que los humanos y los animales aprenden a través de la experiencia. Piensa en cómo aprendiste a montar en bicicleta: al principio, es probable que cayeras varias veces. Pero, cada vez que cometías un error, aprendías de él, ajustando tu comportamiento hasta dominar la habilidad.
Así funciona el aprendizaje por refuerzo, donde un modelo de IA toma decisiones, recibe una «recompensa» o «penalización» en función de si su acción fue correcta o no, y luego ajusta sus acciones en el futuro con el objetivo de obtener la mayor recompensa posible. Este proceso, aunque más errático al principio, permite que el modelo descubra soluciones de manera autónoma, sin necesidad de intervención humana directa.
Por qué resulta innovador el aprendizaje por refuerzo
El uso de aprendizaje por refuerzo en el entrenamiento de DeepSeek-R1-Zero es especial porque permite que el modelo aprenda a tomar decisiones a través de la interacción con su entorno, optimizando sus acciones de forma autónoma para lograr un objetivo específico.
En el caso de DeepSeek-R1-Zero, un modelo de inteligencia artificial basado en redes neuronales profundas, el aprendizaje por refuerzo es útil en escenarios complejos donde las decisiones deben tomarse de manera secuencial y adaptativa. Algunas características clave de este enfoque incluyen:
- Exploración y explotación: el modelo tiene que equilibrar entre explorar nuevas acciones (exploración) y usar las acciones que ya sabe que funcionan bien (explotación), lo cual es crucial en ambientes dinámicos o inciertos.
- Optimización continua: a medida que el modelo interactúa más con su entorno, va ajustando sus parámetros para maximizar la recompensa, lo que permite una mejora continua en la toma de decisiones.
- Autonomía en el aprendizaje: el modelo no depende de datos preexistentes para aprender; en cambio, puede mejorar su rendimiento con el tiempo a través de la experiencia, lo que lo hace altamente adaptable a situaciones nuevas o en evolución.
Etapas en el proceso de entrenamiento de DeepSeek-R1-Zero
La clave del éxito de DeepSeek se encuentra en la combinación de varias fases de entrenamiento que han permitido al modelo aprender de manera autónoma y mejorar continuamente.

A continuación, te explicamos cada una de estas etapas fundamentales.
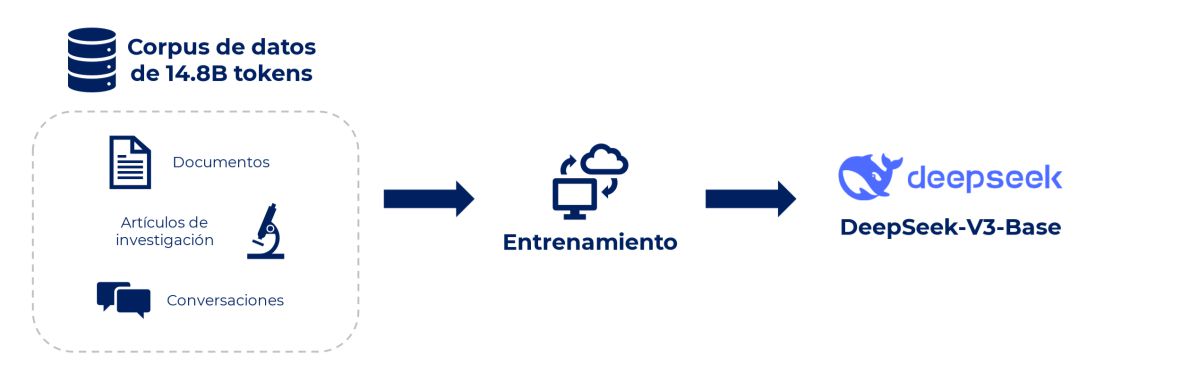
1. DeepSeek-V3 Base: creación de la fundación
La primera fase del proceso de entrenamiento de R1 comenzó con la creación de una base sólida, que sería la base de todo el modelo. Para ello, DeepSeek entrenó el modelo utilizando 14.8 billones de tokens, una cantidad monumental de datos que incluye todo tipo de textos, desde artículos de investigación hasta conversaciones cotidianas. Estos «tokens» son fragmentos de texto, como palabras o partes de palabras, que el modelo utiliza para aprender el lenguaje.
Con esta enorme cantidad de datos, el modelo comienza a identificar patrones complejos en el lenguaje: cómo se construyen las frases, cómo se relacionan las palabras entre sí y cómo se pueden usar en distintos contextos. Aunque en esta fase el modelo aún no es capaz de tomar decisiones complejas, está construyendo el entendimiento básico del lenguaje, las relaciones entre conceptos y la estructura de las respuestas. Este es el punto de partida para que el modelo pueda abordar tareas más avanzadas.
2. R1-Zero: aprendizaje por refuerzo puro
La fase siguiente fue la más innovadora: R1-Zero. En esta etapa, el modelo fue entrenado completamente mediante aprendizaje por refuerzo, un enfoque que es bastante diferente al aprendizaje supervisado tradicional. En lugar de ser alimentado con respuestas correctas por un entrenador humano, el modelo tiene que aprender a través de la experiencia.
El modelo R1-Zero fue puesto a prueba mediante una serie de interacciones, donde recibió retroalimentación basada en los resultados de sus acciones. A través de este proceso de prueba y error, el modelo fue capaz de «descubrir» soluciones por sí mismo, mejorando gradualmente sus respuestas.
Este enfoque le permitió al modelo desarrollar estrategias de razonamiento únicas, ya que no dependía de patrones predefinidos. El modelo aprendió a tomar decisiones informadas y a ajustar su comportamiento de acuerdo con las recompensas obtenidas, sin necesidad de intervención humana directa.
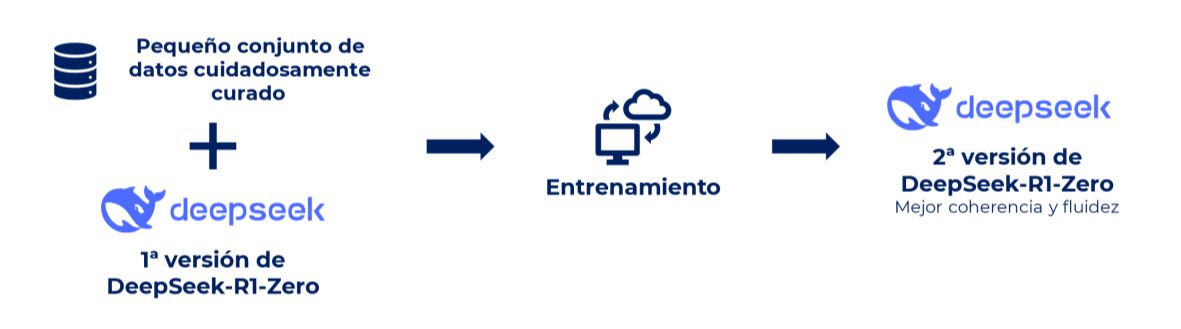
3. Cold Start SFT: mejorando de la coherencia
En este punto, el modelo ya tenía una comprensión básica del lenguaje y cómo responder a preguntas, pero sus respuestas podían ser erráticas o poco claras. Para mejorar esto, el equipo de DeepSeek introdujo un conjunto de datos pequeño, pero altamente curado. Este conjunto de datos no era tan masivo como los anteriores, pero estaba compuesto por ejemplos de alta calidad, cuidadosamente seleccionados para mejorar aspectos específicos como la coherencia, fluidez y relevancia de las respuestas.
Con esta intervención supervisada, el modelo comenzó a afinar su capacidad para ofrecer respuestas más estructuradas y claras, mejorando su capacidad para entender lo que realmente se le está pidiendo y cómo responder de manera coherente y fluida.
4. Última fase de RL: perfeccionamiento final
La fase final del entrenamiento de R1 fue una última etapa de aprendizaje por refuerzo, pero esta vez con un enfoque más refinado. Aquí, el modelo fue sometido a una fase de optimización final, donde se hicieron ajustes más finos para asegurar que el modelo fuera consistente, multilingüe y fácil de usar.
En este paso, el modelo siguió aprendiendo de sus interacciones, pero ahora con un enfoque más específico en la calidad y la precisión. Además, se buscó que el modelo fuera capaz de responder en varios idiomas de manera fluida, lo cual es esencial en un entorno globalizado. Esta fase fue crucial para garantizar que R1 pudiera manejar una variedad de consultas de manera efectiva, sin importar el contexto o el idioma en que se formulara la pregunta.
Con cada iteración de este proceso, DeepSeek fue afinando aún más la capacidad del modelo, asegurando que sus respuestas fueran precisas, consistentes y útiles para las personas usuarias finales. La combinación de aprendizaje por refuerzo con entrenamiento supervisado permitió que el modelo no solo aprendiera de manera autónoma, sino que también se ajustara a los estándares de calidad necesarios para su uso en el mundo real.
El desarrollo de DeepSeek R1-Zero marca un avance significativo en la inteligencia artificial al demostrar el potencial del aprendizaje por refuerzo puro. A través de un proceso de entrenamiento autónomo y optimizado, este modelo ha logrado superar las limitaciones del aprendizaje supervisado tradicional, reduciendo la dependencia de grandes volúmenes de datos etiquetados. Además, su capacidad para aprender de la experiencia, ajustar estrategias de manera continua y ofrecer respuestas cada vez más precisas lo convierte en un referente en tareas de razonamiento y resolución de problemas matemáticos.
¿Quieres aprovechar el poder de la IA Generativa para impulsar tu negocio? Contamos con un equipo experto en IA Generativa y Data que han desarrollado GenIA Ecosystem, un ecosistema de soluciones propias de IA conversacional, generación de contenido y data adaptadas a las necesidades de cada mercado y cliente. ¡Contáctanos!

¿Quieres más información sobre DeepSeek-R1-Zero?
Contacta con nuestro equipo experto en IA Generativa
