

En los proyectos de BI, donde la velocidad y precisión son esenciales, resulta crucial contar con una estructura de datos robusta y bien documentada. En este contexto, el uso de un buen diccionario de datos se convierte en un recurso de valor incalculable. Este diccionario debe proporcionar una visión panorámica de todas las tablas de la base de datos del proyecto, así como detallar la estructura de cada una (columnas, tipos de datos, campos no nulos, restricciones, etc.), proporcionando así un marco sólido para el desarrollo del proyecto.
En este artículo mostraremos la plantilla que desarrollamos desde el equipo de Oracle y cómo agilizamos el proceso de creación de tablas en base de datos gracias a un script de Python.
La plantilla del diccionario de datos para proyectos de BI
La estructura de la plantilla que desarrollamos consta, en su estado actual, de los elementos básicos para describir las tablas del modelo y sus características. Consta de varias hojas de propósito general y de una hoja para cada tabla. Describimos a continuación cada una de ellas.
![]()
Hoja “Control de Cambios”
Esta hoja inicial permite llevar el seguimiento de los autores del documento y controlar sus versiones. El script de Python no utiliza esta hoja, por lo que puede modificarse su estructura a placer sin afectar su funcionamiento.
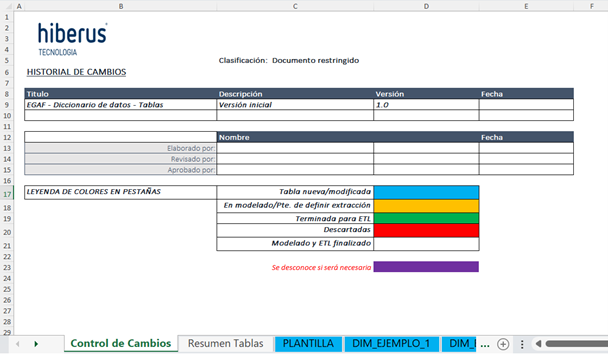
Hoja «Control de Cambios»
Hoja “Resumen Tablas”
Esta hoja es la pieza central del diccionario de datos. Posee una fila por cada tabla, donde incluye su nombre, esquema, enlace a la hoja individual de la tabla, etc. El script solo tendrá en cuenta las dos primeras columnas de esta hoja, por lo que la estructura del resto puede modificarse sin afectar su funcionamiento. Es importante fijarse en que se mantiene una columna vacía a la izquierda del nombre de tabla. En esta marcaremos con una “x” las tablas que queramos que el script tenga en cuenta a la hora de generar el código SQL.
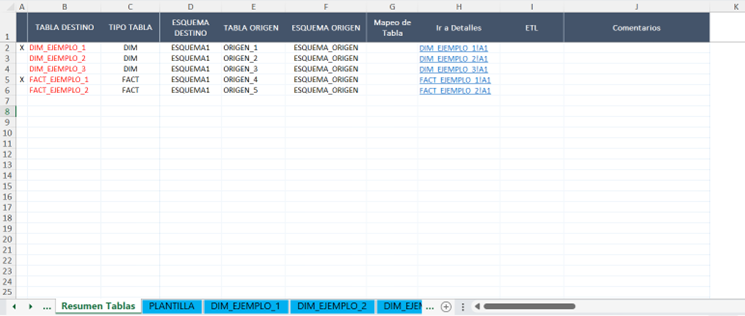
Hoja «Resumen Tablas»
Una hoja por cada tabla
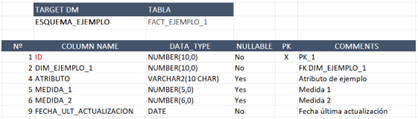
Para cada tabla descrita en la pestaña “Resumen tablas”, crearemos una hoja nueva que se deberá llamar exactamente igual que la tabla. Esta hoja incluye, entre otras cosas, una tabla donde indicamos su estructura (nombres de columna, tipos de datos, nulos, campos de la clave primaria y comentarios). Se incluye también un enlace para volver al resumen. A partir de esta hoja, el script de Python generará automáticamente el código SQL para crear la tabla.
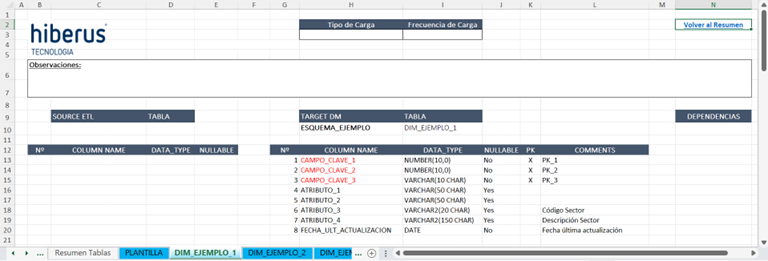
Hoja para la tabla de ejemplo «DIM_EJEMPLO_1»
Creación automática de código SQL de creación de tablas
Una vez completado el diccionario, surge la necesidad de traducir esta información en la creación real de tablas en la base de datos. Hacerlo a mano puede ser costoso si la cantidad de tablas es grande, además de que estaríamos repitiendo trabajo (pues ya hemos escrito toda la estructura de las tablas en el diccionario) y nos expondríamos a más errores manuales. Gracias al uso de una plantilla bien estructurada como la que hemos definido, podemos utilizar en su lugar un script que lea el Excel y genere de forma automática el código de SQL de creación de las tablas.
En nuestro caso, utilizamos Python para esta tarea. Desarrollamos un script auto_tablas_sql.py al que llamamos pasándole el nombre de nuestro Excel del diccionario de datos como parámetro. Para ello utilizamos el módulo de Python xlwings, que nos proporciona métodos para recorrer de forma sencilla las celdas de un libro de Excel. Su documentación oficial puede encontrarse aquí.
El script generará en el directorio de trabajo los siguientes elementos:
- Un archivo sql que contiene todos los script de creación de tablas, uno detrás de otro. Este es ideal para copiar, pegar y ejecutar en la hoja de trabajo de SQL.
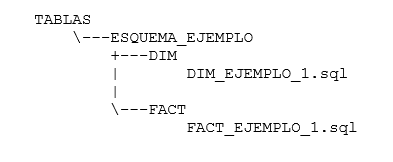
- Un árbol de directorios que organiza cada script de creación de tabla en un archivo individual, cuyo nombre es el mismo de la tabla. La estructura del árbol de directorios consta de una raíz llamada TABLAS que contiene una carpeta por cada esquema. Cada esquema contiene una carpeta para cada “prefijo” de tabla (en nuestro caso lo que hay antes del primer guion bajo, por ejemplo DIM o FACT). Cada una de estas carpetas contiene los archivos individuales correspondientes.
Como ya mencionamos anteriormente, el desarrollador debe escoger qué tablas del Excel tendrá en cuenta el script, utilizando la primera columna del resumen como casillas de marcado. Aquellas que tengan texto (por ejemplo, una “x”) indicarán al script que debe procesarse la tabla indicada en esa fila. La re-ejecución del código sobrescribirá los contenidos ya existentes.
Para mayor flexibilidad (y por si en el futuro pudiesen ocurrir cambios en la estructura de la plantilla), no conviene tener hardcodeadas las coordenadas de cada elemento en el código. Por ello se creó un archivo config.py para recogerlas como variables, pudiendo modificarlas en cualquier momento sin editar el script principal. Este archivo de configuración también nos permite activar o desactivar la creación del output.sql y/o del árbol de directorios, en caso de que solo nos interese uno de ellos.
Para ejecutar el código cómodamente desde cualquier directorio del sistema, hemos creado un ejecutable auto_tablas_sql.bat que ejecuta el script de Python, utilizando como directorio de trabajo aquel desde donde se ejecute. Por último, hemos añadido su ruta a la variable de entorno PATH.

Archivos finales del programa
Ejemplo de uso
A continuación probaremos la ejecución del script. Utilizaremos como ejemplo dos tablas DIM_EJEMPLO_1 y FACT_EJEMPLO_1.
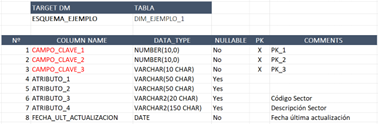
Indicamos en nuestra hoja “Resumen Tablas” que se deben procesar las tablas DIM_EJEMPLO_1 y FACT_EJEMPLO_1:
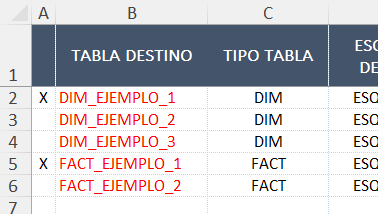
Hoja de resumen con las tablas DIM_EJEMPLO_1 y FACT_EJEMPLO_1
Llamamos al script desde la ruta donde queremos que se creen el archivo output.sql y el árbol de carpetas. Le añadimos como argumento la ruta del diccionario de datos y ejecutamos.
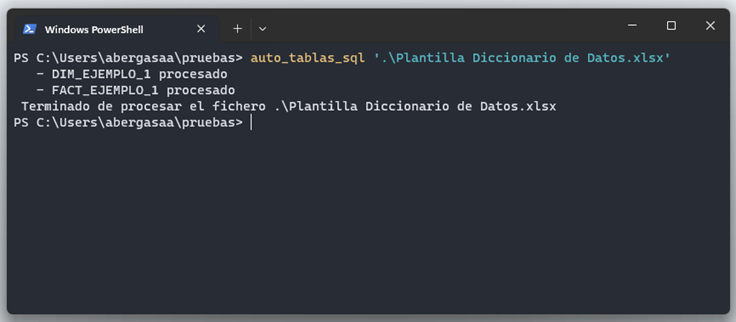
La consola nos confirma que las tablas DIM_EJEMPLO_1 y FACT_EJEMPLO_1 se han procesado (son las que habíamos marcado con una “x” en la hoja de resumen). Finalmente, comprobamos el resultado.
Contenido de output.sql
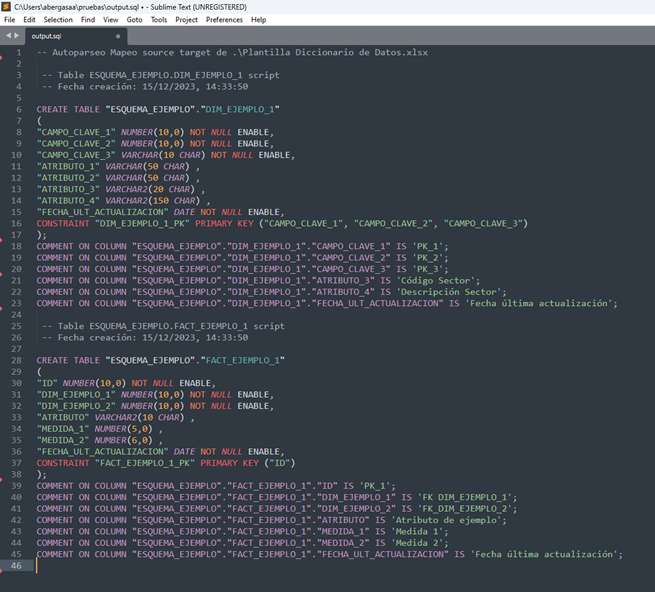
Fichero output.sql generado por el script
Árbol de directorios creado:
Hecho esto, el desarrollador puede simplemente copiar, pegar y ejecutar el código de output.sql en la hoja de trabajo de SQL para crear todas las tablas que haya marcado en el diccionario de datos, incluyendo ya además los comentarios de columna y la clave primaria.
Hecho esto, el desarrollador puede simplemente copiar, pegar y ejecutar el código de output.sql en la hoja de trabajo de SQL para crear todas las tablas que haya marcado en el diccionario de datos, incluyendo ya además los comentarios de columna y la clave primaria.
Conclusión
La combinación de un diccionario de datos bien diseñado y la automatización de generación de código de creación de tablas a través de scripts no solo mejora la eficiencia del desarrollo, sino que también reduce la posibilidad de errores manuales. Este enfoque proporciona a los desarrolladores una herramienta valiosa para gestionar y mantener la integridad de la estructura de la base de datos en proyectos de BI, contribuyendo así al éxito y la calidad del producto final.
Nuestro equipo de Data & Analytics cuenta con un equipo especializado en Business Intelligence. Gracias a las herramientas de BI, ayudamos a nuestros clientes a integrar diferentes fuentes de datos, facilitar la realización de informes y elaborar los análisis adecuados para mejorar la toma de decisiones.

¿Quieres más información sobre nuestros servicios de Business Intelligence?
Contacta con nuestro equipo de expertos en BI
