

Henneo es uno de los mayores grupos empresariales en España involucrado en el sector de comunicación mediática y periodismo, dueño de varias empresas periodísticas y webs, con millones de visitas diarias y usuarios de todas partes del globo. Entre los medios que forman parte del grupo, se incluyen periódicos como
Henneo confío en Hiberus Tecnología, para impulsar el proyecto de mejora de experiencia de usuario y de incremento de visitas, utilizando técnicas de inteligencia artificial.
El reto: Poner en producción un mecanismo de recomendación de noticias, escalable, autónomo, capaz de incrementar visitas repetidas y fidelizar a los usuarios.
Inteligencia artificial en medios de comunicación
Uno de los problemas que más se están encontrando empresas, no solo del sector periodístico, si no de cualquier otro sector, es maximizar los beneficios y optimizar sus inversiones en marketing e infraestructura. En este caso, al tratarse de un modelo de negocio cuyo producto principal es el contenido web, maximizar las ventas requiere maximizar lecturas del contenido.
No obstante, para maximizar ventas eso no es suficiente. Necesitan ser capaces de presentar el producto perfecto a la persona más interesada, en el mejor momento de compra posible. Se trata de maximizar las ventas con un fit perfecto entre cliente, producto, y momento de compra.
Una de las mejores herramientas que podemos aprovechar para optimizar esta relación, es la inteligencia artificial aplicada a la recomendación de productos.
Henneo nos solicitó un recomendador de noticias que mejorase las visitas recurrentes aprovechando datos obtenidos de los millones de impactos que generan diariamente, en una arquitectura de big data escalable y sostenible no solo dentro de la empresa, pero en el grupo empresarial.

Nuestra metodología de trabajo para crear un recomendador de noticias
Utilizamos para organizar el proyecto y los objetivos del mismo metodologías ágiles, una mezcla de la casa entre Kanban y Scrum. Con ciclos de trabajo fijos, pero con una gestión del backlog más flexible a la hora de definir tareas e historias permitiendo cambiarlas según nuevos descubrimientos encontrados en nuestros experimentos de ciencia de datos, obstáculos a la hora de coordinarse con otros departamentos dentro del cliente, y en base a los cambios en nuestro conocimiento sobre el problema trabajado.
El proyecto se organizó principalmente en 5 fases
1. Investigación de problema de negocio, algoritmos, y diseño de arquitectura
Pues bien, una vez claro exactamente el data product que deseábamos trabajar, y la solución que buscaríamos aportar, tocó realizar labor de investigación a varios niveles:
Científica:
Nos tocó revisar la documentación científica existente sobre aplicaciones de machine learning aplicada a recomendación, y más importante, aplicadas a recomendación de contenido basado en noticias.
Revisar cuales algoritmos eran más útiles / rápidos para un primer prototipo, buscando la mayor probabilidad de éxito a la hora de elegir. Tuvimos que consultar varias docenas de papers y artículos, para poder entender todas las posibilidades, algoritmos que podíamos utilizar, etc.
Con esta investigación llegamos a varias hipótesis. Varias aplicaciones de negocio que podíamos darle a la inteligencia artificial. Para facilitar la lectura del caso de éxito, nos centraremos en solo una de las que exploramos y pusimos en producción. La hipótesis que pensamos era la siguiente:
“¿Puede un usuario, que lee un artículo en un momento dado, estar más interesado en ese momento de leer otros artículos de la misma temática?”
Es decir, si un usuario lee un artículo, por ejemplo de política, sí le recomiendo otro de política en ese mismo instante; ¿Ese usuario estará más interesado en eso, que otros artículos más populares de otras temáticas? ¿Puede que en ese momento, esté más predispuesto a consumir política, frente a otros momentos?
Se nos ocurrió, que si esta hipótesis era correcta, podríamos usar esto, por ejemplo aumentar las visitas de artículos nuevos que poca gente conoce, o artículos antiguos que normalmente no se consumen tanto. Este experimento mental nos aportaría información interesante que guiaría las siguientes fases de investigación, por ejemplo la arquitectónica que veremos en el siguiente párrafo.
Hacer un algoritmo de esas características, requeriría alimentar a nuestra inteligencia artificial de noticias, que fuese capaz de traducir el texto en la mismas a un lenguaje matemático (por ejemplo, a vectores) y que con eso, fuese capaz de detectar qué artículos son de temáticas parecidas, recomendando solo los más parecidos. Todo esto diariamente (publicamos nuevos artículos cada día). Requerimos una procesamiento y entrenamiento constante, una base de datos conectada de poca latencia, entre otras cosas.
Esta fue la primera hipótesis que decidimos explorar e implementar. Encontramos otras, que también investigamos y pusimos en producción usando las fases sucesivas de refinamiento del mecanismo.
Con nuestra investigación, también descubrimos varios algoritmos matemáticos concretos que podríamos usar para llevar a la realidad una prueba de esta hipótesis, Latent Dirichlet Allocation (LDA), Latent systematic analysis (LSI, o LSA), y TF-IDF (Term frequency- Inverse Document Frequency), entre otros.
Arquitectónica:
En esta fase también tocó investigar arquitecturas en la nube que podían soportar un algoritmo funcionando en producción, principalmente en la herramienta en la nube que utilizaba nuestro cliente para su inteligencia interna, aprovechando así la infraestructura existente.
2. Desarrollo de primer prototipo funcional
Toda esta investigación, nos permitió planificar con fundamento los hitos, tareas e historias a esperar durante todo el proyecto. Creamos así un roadmap que nos permitió alinear expectativas, backlog y entregables.
Con una idea fundamentada, lo siguiente es ponerse manos a la obra, y resolver lo antes posible una incógnita importante: tener un algoritmo que funcione con nuestros datos y nuestros objetivos.
Dependiendo de la experiencia que se tenga, la documentación científica existente, y las librerías disponibles ya desarrolladas, implementar un algoritmo de inteligencia artificial puede llevar mucha experimentación, prueba y testeo de hipótesis (por eso lo llaman ciencia de datos).
Lo primero fue investigar qué librerías en python había ya creadas, con los algoritmos que nos interesaba implementar, nos preocupamos porque fuera:
- Rápido y fiable en su cálculo, es decir, vectorizado en sus computaciones
- Que estuviese bien documentado, bien mantenido y usado por otras personas,
- Que tuviese la posibilidad de escalar, con comùtación distribuida ( para cuando tocase manejar muchos datos).
A partir de esos requisitos cumplidos, elegimos la que tuviera más algoritmos parecidos a nuestra necesidad ya creados , y que fuera más fácil de utilizar.
Nuestra primera elección fue un paquete llamado Gensim, especializado en procesamiento de texto, pues recordemos, estamos trabajando con datos de tipo texto, no numéricos, eso requiere usar técnicas de procesamiento de lenguaje para poder aprovechar esos datos.
Con una primera elección definida, el siguiente paso fue implementar un prototipo de nuestro algoritmo recomendador, con esa librería.
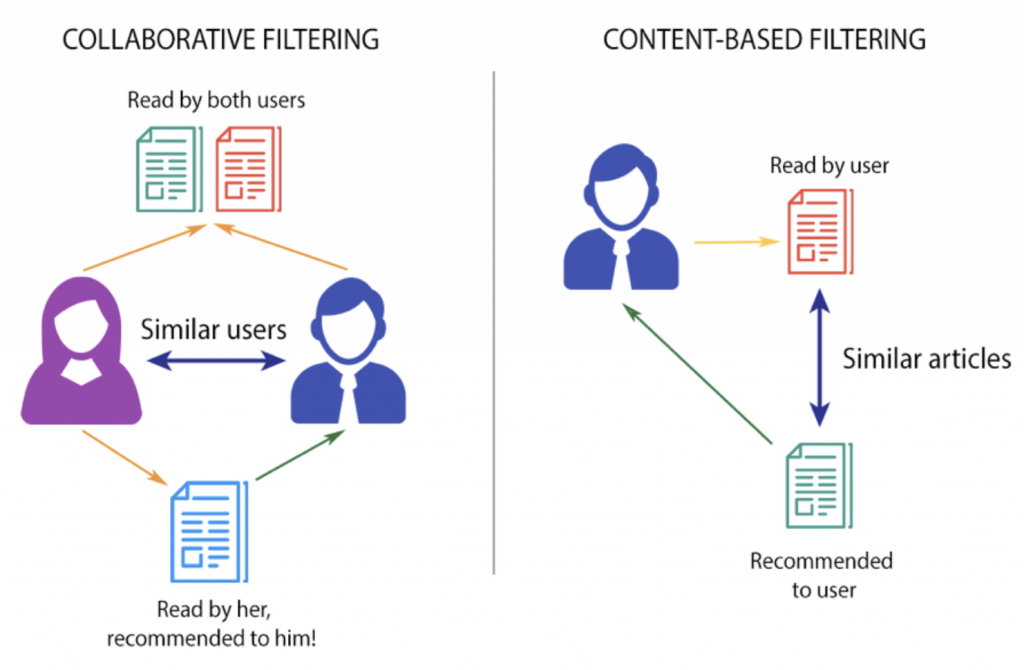
3. Evaluación y optimización offline de prototipo funcional
El siguiente paso fue optimizar nuestro algoritmo. Ya tenemos un primer prototipo de algoritmo codificado y funcionando, hemos comprobado que nuestra librería elegida es efectiva en su labor, pero, que funcione, no significa que funcione lo mejor posible.
Aquí viene el proceso de diseñar experimentos internos, que nos permitan definir la tasa de éxito del recomendador cuando esté en producción (recordemos, el objetivo es aumentar visitas repetidas, hay unas expectativas de negocio que cumplir). Esos experimentos además nos permitirán mejorar esa tasa esperada lo máximo posible antes de que nuestros usuarios vean recomendaciones.
Los experimentos consisten en probar distintas “ideas” con método científico para descubrir o probar “hipótesis” que tenemos sobre el funcionamiento de las matemáticas del algoritmo o algoritmos, en relación al caso de negocio. El objetivo es aprender tanto como podamos (basándonos en datos) sobre la relación entre el algoritmo y el problema, y empezar a notar las diferencias de lo que se ha observado en la documentación académica con lo que ocurre en realidad.
Esto permite definir la mejor combinación (hasta entonces descubierta) entre como tiene que recibir los datos la inteligencia artificial, y como tiene que configurarse su matemática, para dar el mejor resultado posible para los objetivos de negocio. En esta fase también es donde ponemos a competir distintos algoritmos para ver si hay alguno mejor al que originalmente escogimos.
Esta fase requirió volver a revisar documentación científica entorno a métodos para evaluar el problema, como funciona la matemática de los algoritmos elegidos, entre otras cosas.
Concluímos esta fase, decidiendo pasar a producción con un algoritmo distinto al que habíamos apostado originalmente, con una combinación de hiper parámetros definida.
4. Puesta en producción: de prototipo funcional a producto mínimo viable (MVP)
Poner esta fase como Cuarta, es un poco falso, en el sentido de que, una vez se teníamos clara la arquitectura del producto en la fase 2, se empezó a adelantar todo lo que se pudo la preparación de la arquitectura.
No obstante, sí es cierto que no es hasta que se tiene el algoritmo preparado, y empaquetado en una librería propia, que este se integra con la arquitectura. Y es que es necesario probar distintas cosas, como la velocidad de ejecución del algoritmo en la arquitectura. Este se conecta e integra con las distintas APIs que necesita, las bases de datos, el servidor que se encarga de presentar la recomendación en la web al usuario en formato html, es necesario hacer que el algoritmo que antes funcionaba en local ahora procese los datos en la forma en que se reciben en la nube, y devuelva las recomendaciones en el tipo de objeto que el servidor web que muestra la recomendación, necesita. Toca hacer el trabajo de “Data engineering” y “AI engineering” y poner el algoritmo en producción.
Una vez todo está listo, se lanza, para ver cómo responden los clientes, los visitantes web, a la inteligencia artificial.
Aquí unos ejemplos de cómo se veía el recomendador, en producción:
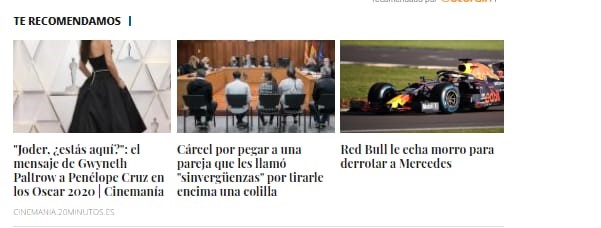
Tengamos en cuenta que solo el artículo de la derecha es el recomendador, los otros dos de la izquierda sirven como grupo de control, para asegurar diferencia de clicks cuando recomendamos al usuario artículos de la misma temática, con respecto a cuando recomendamos lo más visto.
5. Mejora continua y exploración de nuevos algoritmos
El producto mínimo viable cumplió los objetivos iniciales del proyecto. Se consiguió poner en producción, de manera escalable, efectiva y aportando valor. A partir de aquí, queda utilizar la experiencia y know-how obtenido para encontrar nuevas formas dentro del propio negocio, de incrementar el valor aportado.
La aplicación de Machine Learning en todo tipo de sectores no hecho más que comenzar. Desde el equipo de Data & Analytics de Hiberus estamos respondiendo a estos desafíos con soluciones concretas, viables, que permiten trabajar sobre hipótesis de negocio de manera científica, pero a la vez cercanas a las necesidades de la industria.
