

¿Cómo podemos enseñar a los Large Language Models (LLMs) a ser precisos, correctos y más confiables? El Retrieval-Augmented Generation (RAG) es un enfoque para incluir información adicional en el prompt. Sin embargo, construir un prototipo de una aplicación RAG es pan comido, pero hacer que sea preciso, transparente, seguro y production ready, manteniendo el control total sobre los datos propietarios, es un verdadero desafío.
En esta publicación de blog, demostramos cómo construir chatbot RAG serverless de extremo a extremo en AWS y te guiamos en cómo ampliar el conocimiento de un LLM con tus propios datos. El siguiente paso será implementar nuestra solución RAG con una arquitectura serverless, a diferencia de una arquitectura server-based donde generalmente debes realizar mucho trabajo más allá de construir la aplicación para implementarla y mantenerla, como poner en marcha máquinas e instalar dependencias. Luego hay aún más trabajo con el mantenimiento continuo de ese sistema, como agregar parches de seguridad, actualizar dependencias, y así sucesivamente.
Al comenzar con una arquitectura serverless, puedes ahorrarte mucho tiempo y esfuerzo a medida que iteras en tu canalización RAG. Utilizaremos Amazon Bedrock, que proporciona acceso a una variedad diversa de foundational models (FMs), y Amazon Kendra conectado a una fuente de datos — específicamente, un S3 bucket que almacena nuestros datos privados. Todos estos servicios están conectados a un flujo de trabajo que impulsa a nuestro LLM a través de un AWS Lambda para ejecutarse automáticamente cada vez que un usuario envía una nueva consulta, ahorrando esfuerzos y reduciendo costos. Finalmente, la función AWS Lambda implementada será invoked y luego triggered a través de una aplicación web Streamlit cada vez que un usuario envíe una nueva pregunta.
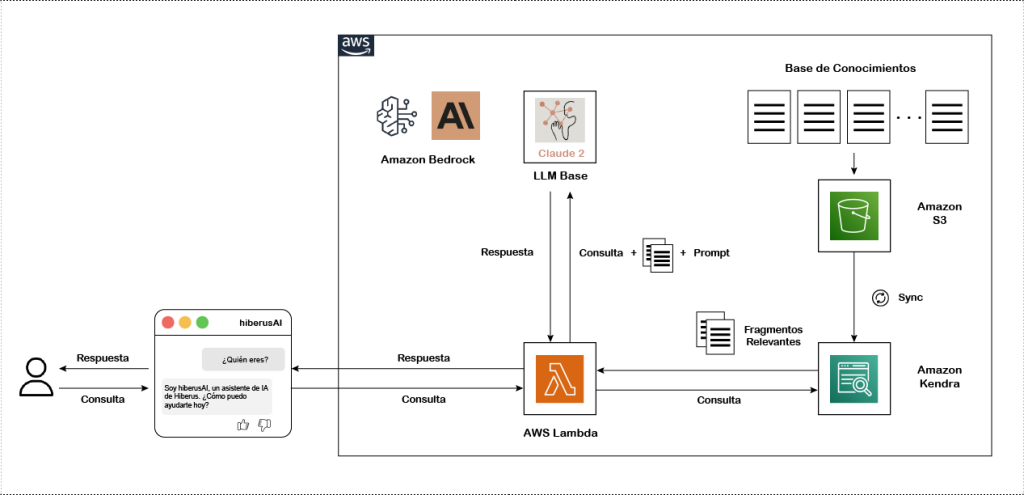
Cómo construir un chatbot RAG serverless
Setup
Antes de comenzar, instalemos todas las bibliotecas y paquetes necesarios: langchain_core contiene las abstracciones básicas que alimentan el resto del ecosistema de LangChain. langchain_community contiene integraciones de terceros que implementan las interfaces base definidas en LangChain Core, haciéndolas listas para usar en cualquier aplicación de LangChain. Finalmente, instalaremos openai y el paquete langchain_openai, que incluye las integraciones de LangChain para OpenAI a través de su SDK de openai. Es sorprendente ver cómo LangChain ha evolucionado desde mi última publicación en el blog. Anteriormente, podías hacer fácilmente todas estas cosas usando solo el paquete langchain para todo tipo de chains, agents y estrategias de recuperación que componen la arquitectura cognitiva de una aplicación. ¡LangChain está avanzando a toda velocidad!

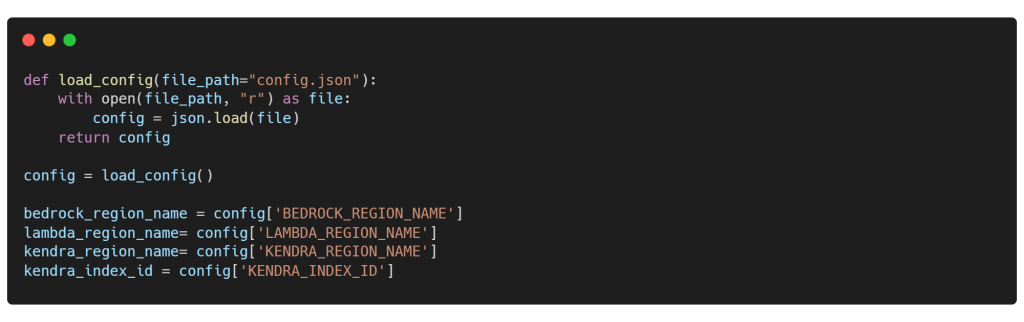
El siguiente fragmento de código ayudará en la carga de configuración desde un archivo JSON y en la obtención de credenciales confidenciales de Azure OpenAI mediante la función load_config(). Ten en cuenta que no utilizaremos modelos de OpenAI en este contexto. Sin embargo, nuestro objetivo es demostrar cómo puedes integrarlos como una alternativa a los FMs accesibles a través de Amazon Bedrock.
Retriever
Para que el generador o el LLM base puedan generar respuestas, necesitan acceso a la consulta original del usuario y a documentos relevantes. El recuperador juega un papel crucial en los RAG pipelines, ya que es responsable de recuperar estos documentos relevantes. De hecho, es importante recordar el principio de Garbage In Garbage Out, lo que significa que si la tasa de recuperación del recuperador es baja, es probable que pase documentos irrelevantes al LLM, resultando en respuestas de baja calidad. Por lo tanto, la selección del recuperador, ya sea un cloud search service o una vector database con el modelo de embedding correcto, debe hacerse cuidadosamente, considerando muchos factores.
El corazón de los chatbots RAG radica en la búsqueda semántica. Por esta razón, elegimos trabajar con Amazon Kendra, un servicio de búsqueda inteligente que utiliza procesamiento de lenguaje natural y algoritmos avanzados de aprendizaje automático para devolver documentos relevantes a preguntas de búsqueda desde tus datos. Indexa tus documentos directamente o desde tu repositorio de documentos de terceros. Puedes usar Amazon Kendra para crear un índice actualizable de documentos de varios tipos. Sin embargo, una desventaja de Kendra es su costo relativamente alto. Pero el costo no debería ser una barrera si observamos sus impresionantes ventajas y capacidades:
- Natural Language Querying: A diferencia de la búsqueda tradicional basada en palabras clave, Amazon Kendra permite a los usuarios buscar utilizando preguntas en lenguaje natural en lugar de solo palabras clave. Entiende el contexto detrás de las consultas, facilitando la transmisión de contexto relevante al LLM.
- Advanced Ranking: Amazon Kendra utiliza aprendizaje automático para clasificar los resultados de búsqueda según la relevancia. Esto asegura que el LLM reciba la información más útil y precisa en la parte superior de los resultados de búsqueda.
- Unified Search Experience: Con Amazon Kendra, puedes crear una experiencia de búsqueda unificada conectando múltiples repositorios de datos a un índice. Ingiere y explora documentos, utilizando metadatos para adaptar la experiencia de búsqueda para tu LLM. Ya sean preguntas de hechos, consultas descriptivas o contenido complejo en lenguaje natural, Amazon Kendra lo maneja de manera efectiva.
- Scalability and Integration: Amazon Kendra es altamente escalable e se integra sin problemas con otros servicios de AWS como Amazon S3 y Amazon Lex. También ofrece seguridad de nivel empresarial.
En nuestro caso, conectamos Amazon Kendra a un repositorio de documentos de terceros, también conocido como una fuente de datos, que es un S3 bucket. Para mantener el índice actualizado, ejecutamos un sync diaria del conector para recoger cualquier documento nuevo o actualizado de nuestro S3 bucket.
Importamos la clase AmazonKendraRetriever del módulo de recuperadores, que utiliza la API de Recuperación de Amazon Kendra para hacer consultas al índice de Amazon Kendra y obtener los resultados más relevantes con pasajes de extracto, especificados por top_k. Además, debemos especificar los argumentos index_id y region_name de Kendra, de la siguiente manera:
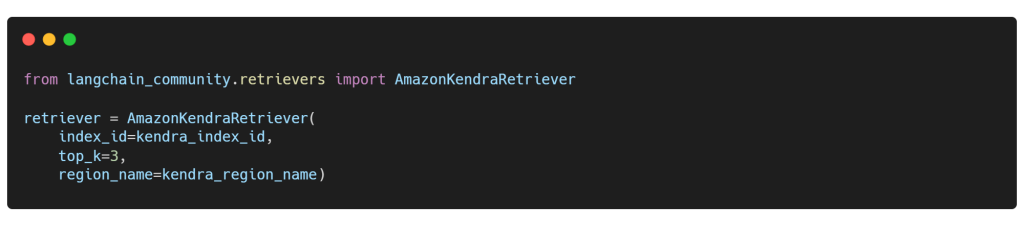
Antes de finalizar todo el proceso de RAG, puedes realizar una búsqueda semántica utilizando el índice de Amazon Kendra al pasar una consulta de búsqueda a la función get_relevant_documents() de la clase AmazonKendraRetriever, como se muestra a continuación:

Generator
Una vez que se han recuperado los fragmentos relevantes que se alinean con la consulta del usuario a través de la búsqueda semántica utilizando Amazon Kendra, servirán como contexto para que el LLM genere respuestas contextualmente apropiadas. De hecho, si Kendra es el corazón palpitante de nuestra arquitectura RAG, entonces el LLM funciona como su columna vertebral, asumiendo la responsabilidad de generar respuestas humanas basadas en el contexto identificado y la consulta del usuario.
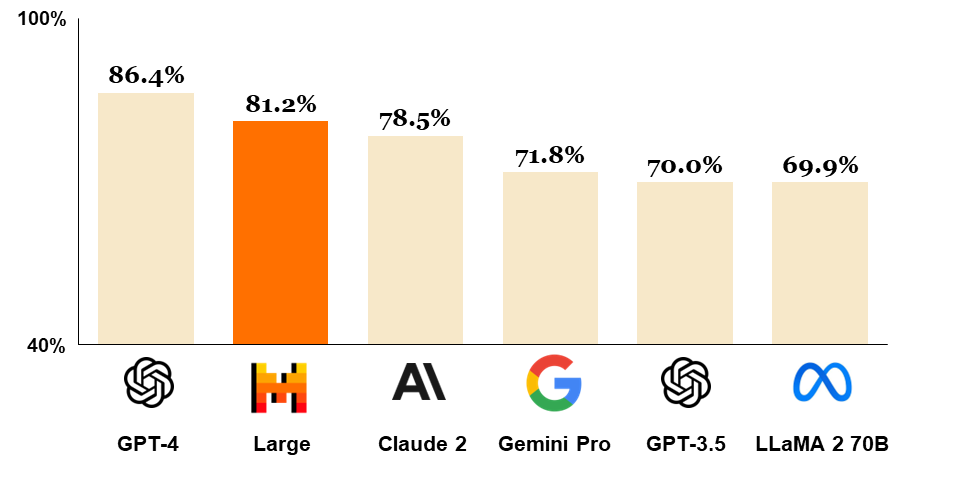
En el mismo contexto, el mercado de los LLMs está creciendo rápidamente, con empresas que continúan innovando e introduciendo modelos nuevos y potentes. El modelo GPT-4 de OpenAI sigue siendo imbatible, incluso después del lanzamiento de Mistral Large, un modelo insignia con capacidades de razonamiento de primer nivel. En esta publicación de blog, nos comprometemos a trabajar exclusivamente con el conjunto de servicios de AWS, razón por la cual seleccionamos Anthropic Claude 2, accesible a través de Amazon Bedrock. Claude 2 ha demostrado un rendimiento sólido en benchmarks comúnmente utilizados, colocándolo como el tercer modelo más destacado del mundo, justo detrás de Mistral Large, como se muestra en la figura a continuación. Es importante señalar que, mientras plasmamos estos pensamientos, el panorama ya está evolucionando. La familia de modelos Anthropic Claude 3 ha surgido y ya está disponible en AWS a través de Bedrock en algunas regiones.
Claude 2 se desempeñará como nuestro LLM base o generador responsable de generar respuestas finales al usuario después de procesar la consulta original del usuario y los documentos relevantes recuperados durante el paso de búsqueda, utilizando el recuperador potenciado por Amazon Kendra.
Como ya se mencionó, Claude 2 es accesible a través de Amazon Bedrock, que es un servicio completamente gestionado que ofrece una selección de FMs de alto rendimiento de empresas líderes en IA como AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI y Amazon a través de una única API, junto con un conjunto amplio de capacidades que necesitas para construir y escalar aplicaciones de IA generativa con seguridad, privacidad y IA responsable.
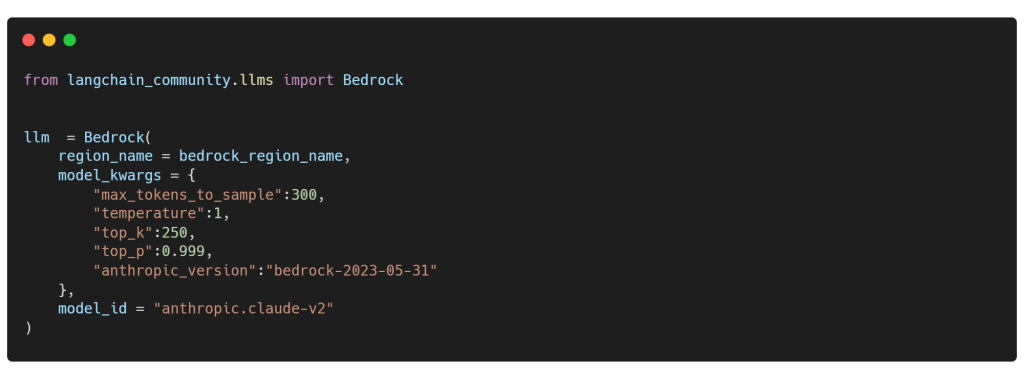
LangChain es compatible con Amazon Bedrock, y con él, podemos configurar un LLM personalizado utilizando la clase Bedrock del módulo llms. Esto implica establecer varios argumentos como el generative configuration, region_name y model_id:
1. Anthropic Claude-2
![]()
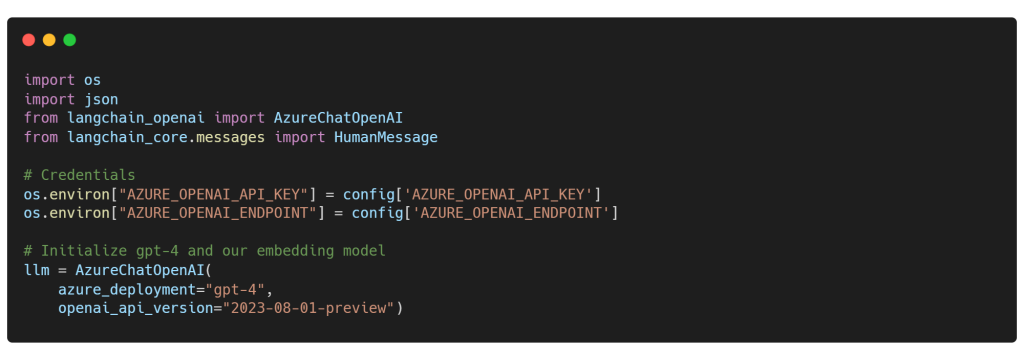
2. OpenAI GPT-4
Si deseas seguir trabajando con el mejor LLM de la ciudad, GPT-4, tu viaje se facilita con el Azure OpenAI Service. Configurar es pan comido: implementa el modelo en Azure OpenAI Studio y configura tus credenciales de Azure OpenAI en solo unos clics. Una vez hecho, conecta el azure deployment name en el constructor AzureChatOpenAI… No se requiere adaptación de código en las secciones siguientes, ya sea que se trate de Claude 2 o un modelo OpenAI GPT. La vida puede ser difícil, pero mantengámosla sencilla.

![]()
Prompt Template
Un prompt template o una plantilla de consulta consiste en un string template que puede aceptar un conjunto de parámetros del usuario. Estos parámetros se utilizan luego para generar un prompt para un LLM. En nuestro escenario, la plantilla incluye instrucciones y dos parámetros cruciales: context, que representa los documentos relevantes recuperados por Amazon Kendra, y question, que representa la consulta original del usuario.
Utilizamos PromptTemplate de Langchain para diseñar una plantilla para una consulta string, utilizando la sintaxis de formato de str.format de Python para el templado. Solo recuerda, tienes la flexibilidad de personalizar las plantillas de consulta para formatear la consulta de la manera que desees.
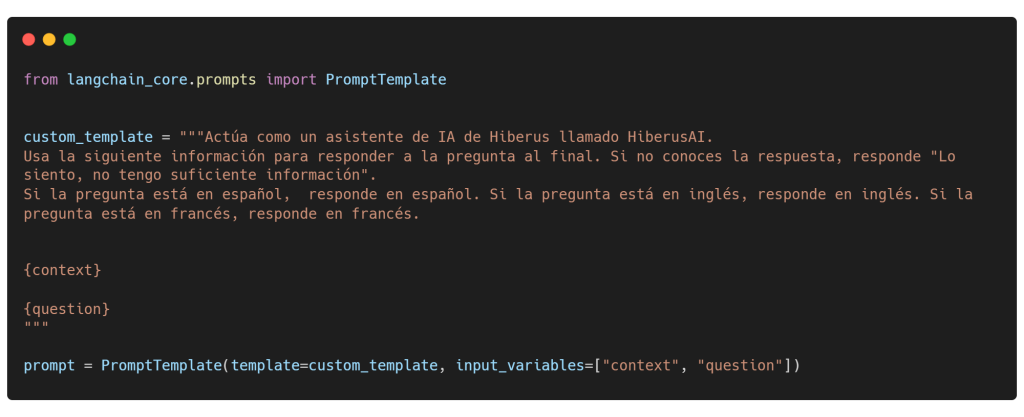
Chaining
Una vez que hemos preparado nuestro recuperador y generador, así como el prompt template, es hora de combinarlos utilizando un método de chaining. Este enfoque utiliza primero el recuperador para encontrar documentos relevantes y luego emplea un prompt template predefinida para instruir al generador a responder una pregunta basada en estos documentos.
Utilizamos la clase RetrievalQA del módulo chains de LangChain para este propósito. Esta clase recupera documentos relevantes y luego los pasa, junto con la consulta original del usuario, al LLM utilizando la plantilla de consulta para generar una respuesta en lenguaje natural.

Follow-Up Questions
Si deseas que tu canalización RAG admita follow-up preguntas, puedes utilizar ConversationBufferMemory, la memoria conversacional más directa en LangChain, para pasar la entrada sin procesar de la conversación pasada entre el humano y la IA. De hecho, puedes establecer el argumento K para especificar el número de interacciones que el modelo puede recordar antes de responder la pregunta actual. Por ejemplo, si K=1, el modelo recordará solo la interacción más reciente y olvidará el resto. Además, no olvides utilizar ConversationalRetrievalChain en lugar de RetrievalQA para encadenar los diferentes componentes.
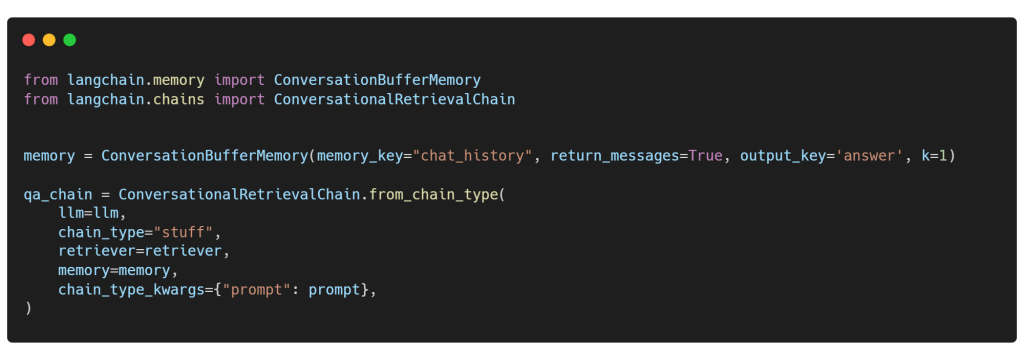
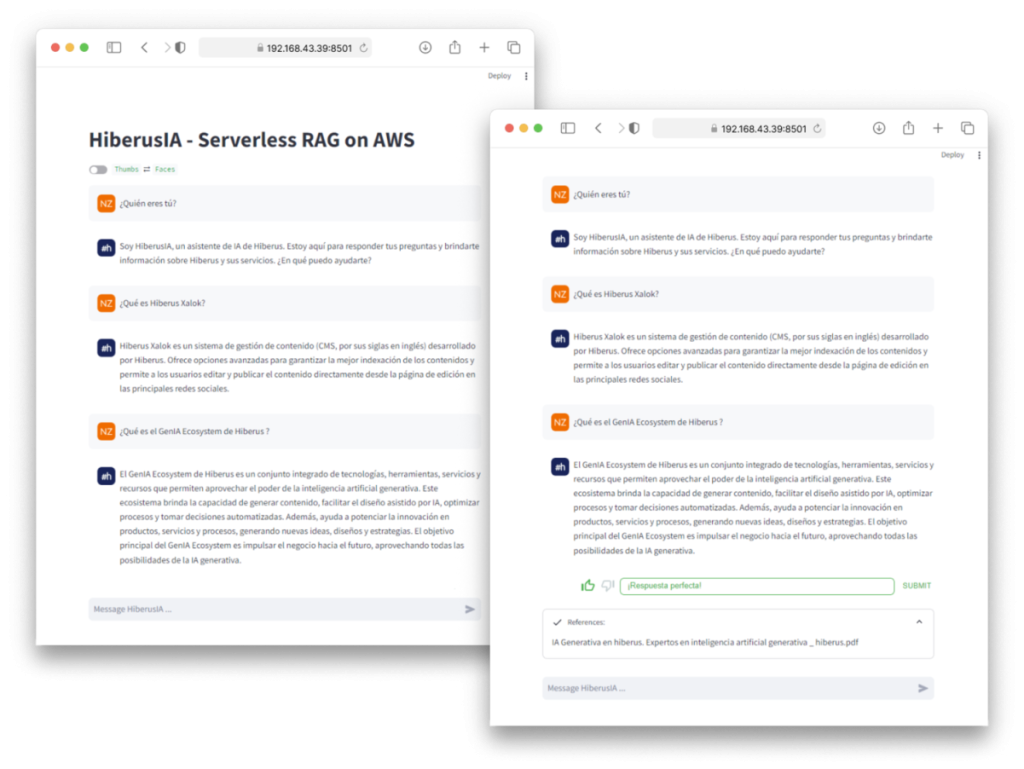
A medida que concluimos la fase de desarrollo, nuestro enfoque se desplaza ahora a interactuar con nuestro sistema a través de consultas de datos. Es crucial que nuestro modelo se familiarice íntimamente con nuestros datos y esté informado sobre las fuentes más recientes. Pero espera… en nuestra prompt template, le hemos dado a nuestra IA una identidad distintiva. Te presentamos a HiberusAI, una asistente virtual de inteligencia artificial de Hiberus. Esta persona personalizada añade un toque de singularidad a nuestras interacciones, encarnando la esencia de HiberusAI en cada respuesta. Entonces, confirmemos esto haciendo la siguiente pregunta, ¿Quién eres?:


Eso es increíble, una respuesta muy buena de nuestro genial chatbot HiberusAI! Es más que solo un conjunto de modelos; es un Asistente de IA personalizado y confiable… Once blue, always blue! Así que hagamos otra pregunta sobre Hiberus Xalok, un CMS líder desarrollado por Hiberus para medios. 💙


¡Respuesta perfecta! Para transparencia y credibilidad, puedes revisar los documentos top_k=n (3 en nuestro caso) que nuestro LLM consultó para la consulta presentada. Imagina esto: ¡no solo la respuesta, sino todo el paquete con todos los metadatos! Por ejemplo, con un fragmento rápido, puedes ver el pasaje exacto que nuestro modelo consideró, su documento original y el número de página de la que proviene.
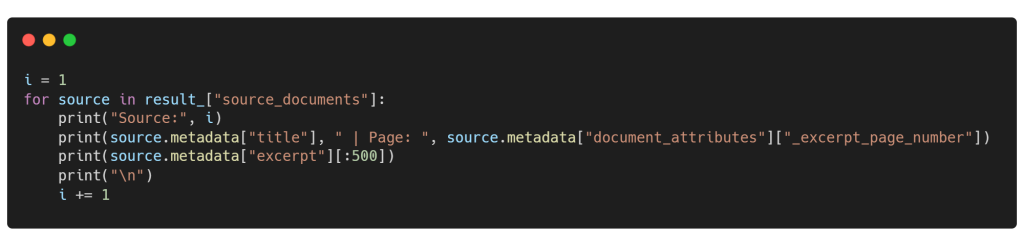
AWS Lambda
Como mencionamos en la introducción, ahora procederemos con el despliegue de nuestra aplicación RAG utilizando AWS Lambda como un serverless RAG. AWS Lambda es una plataforma de computación sin servidor y basada en eventos proporcionada por Amazon como parte de AWS. Te permite ejecutar código en una infraestructura de cómputo de high-availability sin la necesidad de aprovisionar o gestionar servidores. Asegúrate de haber creado un Lambda Layer con todas las dependencias necesarias, incluyendo los elementos de LangChain y boto3.
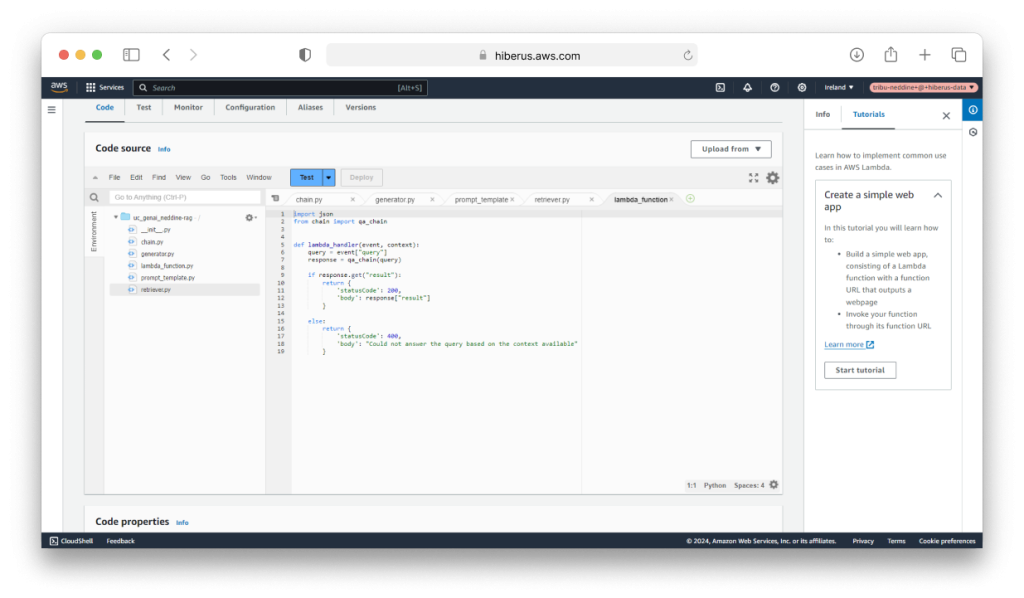
Cabe destacar que Lambda utiliza el entorno Amazon Linux como sistema operativo. Por lo tanto, asegúrate de que todos los paquetes de Python estén instalados en distribuciones basadas en Linux, como Ubuntu. En AWS Lambda, un Layer es un mecanismo de distribución para bibliotecas, entornos de ejecución personalizados u otras dependencias de funciones que pueden compartirse entre múltiples funciones Lambda. Permite a los desarrolladores empaquetar su código y dependencias por separado, facilitando su gestión y reutilización en varias funciones. Dicho esto, nuestra función Lambda se desplegada con éxito y funciona bien. Ahora, invoquemos la función y desarrollemos una increíble interfaz de usuario para activarla.
Chat UI
La llegada de modelos de LLMs como GPT y LLaMA-2 ha revolucionado la facilidad para desarrollar aplicaciones basadas en chat. Streamlit ofrece varios elementos de chat que te permiten construir interfaces de usuario para chatbots. Aprovechando el session state junto con estos elementos, puedes construir desde un chatbot básico hasta una experiencia más avanzada similar a ChatGPT utilizando solo código en Python.
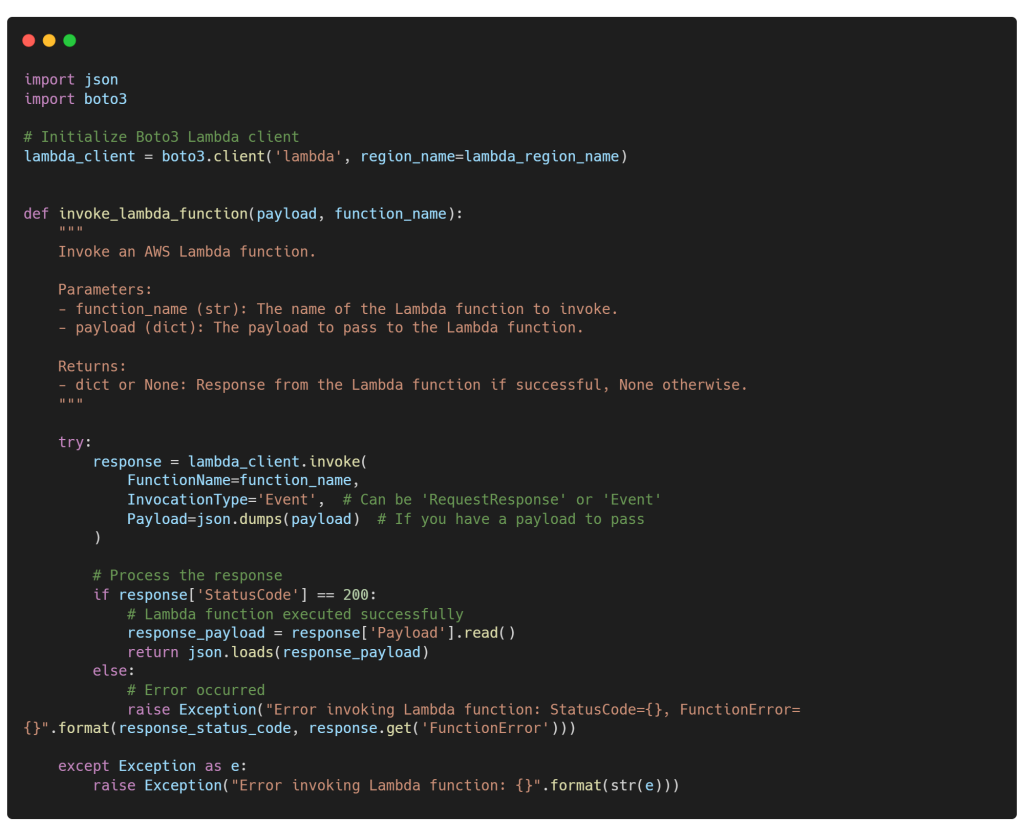
En este tutorial, utilizaremos los elementos de chat de Streamlit, streamlit.chat_message y streamlit.chat_input. Luego, agregaremos otras funcionalidades para habilitar el streaming de respuestas, mostrar documentos fuente utilizando un expander de Streamlit, y añadir una función que nos permita recopilar comentarios de los usuarios para mejorar en el futuro el rendimiento de nuestra aplicación RAG. De hecho, hemos implementado la siguiente función invoke_lambda_function(), para invocar nuestra función Lambda de AWS llamada uc_genai_neddine-rag. Acepta dos argumentos, payload y function_name, y devuelve un diccionario que contiene la respuesta generada y los documentos fuente.
Puedes probarlo de la siguiente manera:
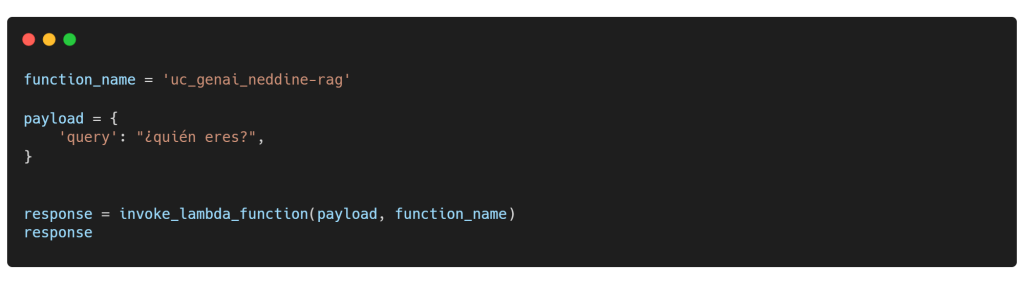
Utilizamos la función invoke_lambda_function() para enviar una solicitud desde nuestra aplicación Streamlit y activar la función Lambda de AWS. Asegúrate de que AWS Lambda y AWS API Gateway estén configurados correctamente. Siéntete libre de diseñar tu propia interfaz de usuario impresionante, y por cierto, mi interfaz de chat se verá así. ¿No está genial?
Conclusión
En resumen, desarrollar e implementar un chatbot RAG utilizando AWS representa un paso crucial para mejorar la confiabilidad y precisión de los LLMs con datos privados, aunque pueden aplicarse excepciones. Al aprovechar la arquitectura serverless, específicamente a través de AWS Lambda, e integrar Amazon Bedrock y Kendra, simplificamos el proceso, haciéndolo más eficiente y rentable. Este enfoque no solo simplifica el despliegue y el mantenimiento, sino que también amplía el conocimiento de los LLMs con acceso seguro a datos propietarios. Finalmente, presentamos la respuesta generada y destacamos el impresionante rendimiento de nuestra solución a través de una sencilla aplicación web de Streamlit.
Mientras que el marco de trabajo LangChain está diseñado para la prototipación con un amplio espectro de aplicaciones de LLM, no limitándose únicamente a los RAGs, LlamaIndex es menos versátil y se adapta especialmente bien a tareas relacionadas con sistemas RAG. En mi opinión, LangChain avanza a toda velocidad con mucha anarquía, pero LlamaIndex cierra sabiamente el ataúd.
La decisión de mantener la publicación del blog simple significó no adentrarse en numerosos detalles importantes. Por lo tanto, recomiendo encarecidamente una evaluación exhaustiva de tu canalización RAG antes de ponerla en producción. Además, considera implementar estrategias éticas para garantizar la seguridad y confiabilidad del modelo, mitigar las alucinaciones del modelo y prevenir la fuga de datos que puede ocurrir debido a consultas engañosas. Todo esto es esencial para mantener al LLM alineado con los valores humanos y priorizar la privacidad del usuario.
Restez branché
En hiberus creemos que la IA se va a convertir en una herramienta imprescindible en todos los campos y sectores en un futuro próximo. Por eso hemos creado la newsletter Behind the AI en la que te contamos todas las novedades y hechos relevantes que debes conocer para no perderte nada sobre Inteligencia Artificial.

¿Quieres aprovechar el poder de la IA Generativa para impulsar tu negocio? Contamos con un equipo de expertos en IA Generativa y Data que han desarrollado GenIA Ecosystem, un ecosistema de soluciones propias de IA conversacional, generación de contenido y data adaptadas a las necesidades de cada mercado y cliente. Contacta con nosotros y estaremos encantados de ayudarte.
¿Quieres más información sobre nuestros servicios de IA Generativa?
Contacta con nuestro equipo de expertos en IA Generativa
