

En la constante evolución de la inteligencia artificial, la Generación con Recuperación Aumentada (RAG, por sus siglas en inglés) ha surgido como una poderosa herramienta que mejora los Modelos de Lenguaje de Gran Escala (LLMs) tradicionales mediante la integración de fuentes de conocimiento externas. Este enfoque simbiótico permite que la IA ofrezca respuestas más precisas y actualizadas, un factor crucial para las empresas y desarrolladores que buscan aprovechar las aplicaciones de IA de próxima generación.
Pero ¿Cómo podemos asegurarnos de que nuestra aplicación RAG no solo sea inteligente, sino también práctica y confiable? El desafío radica en ajustar el rendimiento del pipeline RAG, compuesto de 2 componentes esenciales:
- El Retriever: este componente se encarga de obtener el contexto relevante de una extensa base de datos externa, que guiará al LLM en la elaboración de sus respuestas.
- El Generator: actuando sobre la información recuperada, este componente es responsable de crear la respuesta final sintetizando el estímulo con el contexto adicional.
Para hacer la evaluación de pipelines RAG, es necesario evaluar tanto el Recuperador como el Generador, de forma separada y conjunta. Es similar a cómo un mecánico examinaría las piezas individuales de un coche y su rendimiento general. Para tener una visión clara de la efectividad del RAG, dependerá de los datos. Ahí es donde entran en juego las métricas de evaluación y los conjuntos de datos.
En esta publicación, exploraremos cómo medir adecuadamente el rendimiento de nuestro RAG. Presentaremos ‘Ragas’, una herramienta de evaluación que simplifica este proceso, y discutiremos las métricas estándar que ayudan a rastrear cómo está funcionando su RAG.
Métricas de Evaluación de pipelines RAG
La evaluación de aplicaciones RAG requiere métricas robustas que sean cuantitativas y reproducibles. Categorizamos estas métricas en tres tipos:
Métricas Basadas en Ground Truth (la Verdad de Campo)
La verdad de campo se refiere a las respuestas bien establecidas o fragmentos de documentos de conocimiento en un conjunto de datos que corresponden a consultas de usuarios. Cuando la verdad de campo son las respuestas, podemos comparar directamente la verdad de campo con las respuestas RAG, facilitando una medición de extremo a extremo utilizando métricas como la similitud semántica de la respuesta y la corrección de la respuesta.
A continuación, un ejemplo de evaluación de respuestas basado en su corrección.
- Verdad de campo (Ground truth): Einstein nació en 1879 en Alemania.
- Alta corrección de la respuesta: en 1879, en Alemania, nació Einstein.
- Baja corrección de la respuesta: en Alemania, Einstein nació en 1879.
Donde la verdad de campo son fragmentos del documento de conocimiento, podemos evaluar la correlación entre los fragmentos del documento y los contextos recuperados utilizando métricas tradicionales como Coincidencia Exacta (EM), Rouge-L y F1. En esencia, estamos evaluando la efectividad de la recuperación de aplicaciones RAG.
Generando Verdad de Campo para conjuntos de datos personalizados: si está trabajando con conjuntos de datos privados que carecen de verdad de campo anotada, puede crear datos de prueba utilizando LLMs para formular preguntas y respuestas. Herramientas como Ragas también proporcionan métodos para generar datos de prueba adaptados a sus documentos de conocimiento.
Métricas Sin Verdad de Campo
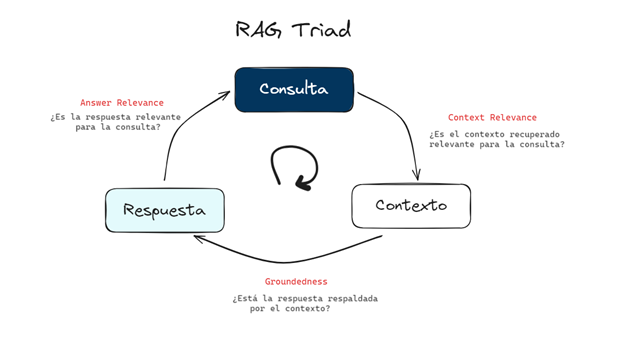
Incluso sin verdad de campo, herramientas como TruLens-Eval emplean el concepto Triada RAG, examinando la interacción entre la consulta, el contexto y la respuesta. Tres métricas correspondientes son:
- Relevancia del Contexto: mide qué tan bien el contexto recuperado apoya la consulta.
- Anclaje: evalúa el grado en que la respuesta del LLM se alinea con el contexto recuperado.
- Relevancia de la Respuesta: evalúa la relevancia de la respuesta final con respecto a la consulta.
A continuación, un ejemplo de evaluación de respuestas basado en su relevancia para la pregunta.
Pregunta: ¿dónde está España y cuál es su capital?
Respuesta de baja relevancia: España está en Europa occidental.
Respuesta de alta relevancia: España está en Europa occidental y su capital es Madrid.
Usando LLMs para puntuar métricas
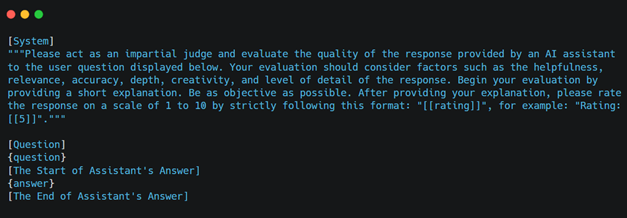
Puntuar estas métricas manualmente puede ser desafiante, pero LLMs como GPT-4 simplifican la tarea. Creando indicaciones bien elaboradas, puedes hacer que GPT-4 evalúe y califique la calidad de la respuesta. Sin embargo, es crucial considerar posibles sesgos y errores en el juicio del LLM. Técnicas avanzadas de ingeniería de indicaciones, como Chain-of-Thought, pueden mejorar la precisión. Muchas herramientas de evaluación RAG vienen con dichas indicaciones preintegradas, agilizando el proceso.
El artículo «Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena» propone un diseño de indicación para que GPT-4 juzgue la calidad de la respuesta de un asistente de IA a una pregunta de usuario. A continuación, un ejemplo rápido:
Ragas: una herramienta para la evaluación eficiente de RAG
RAGAs es una herramienta innovadora de código abierto diseñada para simplificar la evaluación de aplicaciones RAG. Su interfaz intuitiva simplifica el inicio de las evaluaciones al aceptar conjuntos de datos en un formato predefinido. RAGAs proporciona un conjunto robusto de métricas para evaluar tanto los componentes individuales como el rendimiento general de un pipeline RAG.
Métricas a nivel de componente
Componente de Recuperación
- Context recall: evalúa la capacidad del sistema para recuperar toda la información relevante de fuentes de datos externas. Un alto nivel de recuperación de contexto indica una utilización completa de los datos disponibles.
- Context precision: evalúa si todos los elementos relevantes de verdad presentes en los contextos están clasificados más alto o no.
- Context Relevancy: combina aspectos de recuperación y precisión, evaluando la relevancia general del contexto utilizado por el sistema RAG.
Componente Generativo
- Faithfulness: mide la precisión factual de la respuesta generada al dividir el número de afirmaciones correctas de los contextos dados por el número total de afirmaciones en la respuesta generada.
- Answer relevancy: mide qué tan relevante es la respuesta generada para la pregunta utilizando la pregunta y la respuesta.
Métricas de evaluación de extremo a extremo
Además de la evaluación a nivel de componente, RAGAs ofrece métricas de evaluación de extremo a extremo que capturan el rendimiento holístico del sistema RAG:
- Answer Semantic Similarity: evalúa la congruencia semántica entre las respuestas generadas y las respuestas esperadas, indicando la capacidad del sistema para captar y reflejar el significado intrínseco.
- Answer Correctness: avanza en la evaluación para incluir la veracidad de la información proporcionada, afirmando que las respuestas no son simplemente relevantes, sino también verídicas.
En resumen, RAGAs equipa a los usuarios con un conjunto extenso de métricas para evaluar un pipeline RAG de manera integral, tanto a nivel de componente como desde una perspectiva de extremo a extremo. Esto garantiza un análisis completo y matizado de las aplicaciones RAG.
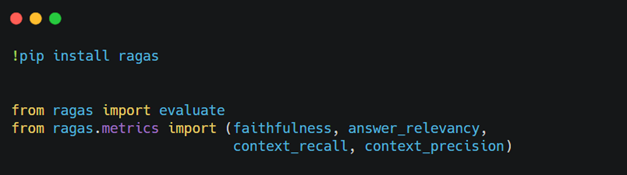
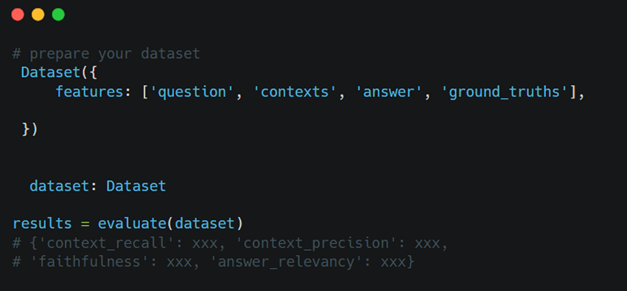
Cómo comenzar con Ragas
Para emplear Ragas en la evaluación de su aplicación RAG:
Resumen
En resumen, la evaluación de los pipelines de Generación con Recuperación Aumentada (RAG) es crucial para mejorar los sistemas de IA que aprovechan fuentes de conocimiento externas.
Nuestra discusión ha cubierto una variedad de metodologías, métricas y herramientas diseñadas para evaluar aplicaciones RAG. Específicamente, examinamos métricas que comparan los resultados contra una verdad de campo, métricas que funcionan sin una referencia de verdad de campo y aquellas que emplean las capacidades analíticas de Modelos de Lenguaje de Gran Escala (LLMs).
Además, destacamos la utilidad de Ragas, una herramienta que simplifica y acelera el proceso de evaluación, proporcionando un conjunto integral de métricas para medir la efectividad tanto de los componentes individuales como del sistema RAG en general. Esto asegura que nuestras aplicaciones de IA no solo sean inteligentes, sino también efectivamente ajustadas a las demandas de la implementación práctica.
En hiberus creemos que la IA se va a convertir en una herramienta imprescindible en todos los campos y sectores en un futuro próximo. Por eso hemos creado la newsletter Behind the AI en la que te contamos todas las novedades y hechos relevantes que debes conocer para no perderte nada sobre Inteligencia Artificial.

¿Quieres aprovechar el poder de la IA Generativa para impulsar tu negocio? Contamos con un equipo de expertos en IA Generativa y Data que han desarrollado GenIA Ecosystem, un ecosistema de soluciones propias de IA conversacional, generación de contenido y data adaptadas a las necesidades de cada mercado y cliente. Contacta con nosotros y estaremos encantados de ayudarte.
¿Quieres más información sobre nuestros servicios de IA Generativa?
Contacta con nuestro equipo de expertos en IA Generativa
