

Cuando nos enfrentamos a problemas de escalabilidad usualmente se piensa en clústeres que permiten alcanzar distribuciones horizontales de carga y garantías de disponibilidad. Por ello, si venimos de usar Pandas y pasamos a Apache Spark, creemos que todos nuestros problemas han sido resueltos. Sin embargo, si definimos a la escalabilidad como la habilidad de un sistema para soportar carga creciente (Kleppmann, 2017, págs. 10, 11), podemos ver que existen diversas maneras alcanzar esta propiedad sin recurrir a entornos necesariamente distribuidos.
Por esta razón, conviene pensar en las características específicas del problema al que nos enfrentamos, los cuellos de botella que lo afligen, y su estructura de programa.
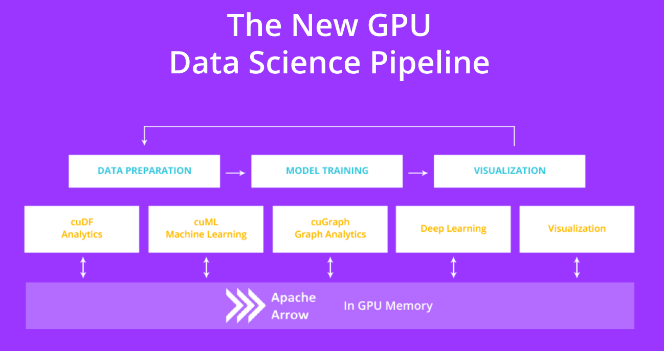
Ilustración 1: USANDO CÓMPUTOS ACELERADOS POR EL GPU EN TODO EL FLUJO DE TRABAJO CON FORMATOS DE DATOS INTERPOPERADOS POR ARROW (FUENTE: HTTPS://GITHUB.COM/RAPIDSAI/CUDF)
Tomemos como ejemplo a Pandas. Wes McKinney, el autor de Pandas y coautor de Apache Arrow, afirmó en un artículo publicado el 21 de septiembre de 2017 que los principales problemas de Pandas para la época eran el rendimiento pobre durante la ingesta y exportación de datos provenientes de bases de datos y archivos, el soporte lento y limitado de algoritmos multinúcleo o paralelos, la falta de conjuntos de datos basados en mapas de memoria, entre otros.
Este artículo, además, resulta interesante en términos históricos pues describe brevemente cuán difícil resultaba analizar datos con Python antes de que él empezara a trabajar con Pandas.

Ilustración 2: Wes McKinney, el creador de Pandas y de Arrow (fuente: https://wesmckinney.com/)
Años después de haber creado a Pandas, luego de haber interactuado con proyectos como Apache Kudu, Apache Spark, Apache Impala y otros, todos comúnmente usados por ingenieros de datos, McKinney reconoció que estas herramientas eran afligidas por problemas similares y que se necesitaba un lugar común para empezar a resolverlos.
Por ello, en 2015 él decidió empezar a diseñar y especificar lo que luego se convertiría en Apache Arrow: un estándar que permite unificar herramientas comúnmente asociadas con dataframes y resolver sus problemas sin duplicar esfuerzos. (McKinney, 2020)
¿Qué es Apache Arrow?
Ahora bien, ¿qué es Apache Arrow? Ésta es una plataforma pensada para aplicaciones analíticas de Big Data que necesitan procesar y mover datos entre sí rápidamente. Para lograr esto, el estándar de Arrow define un formato de datos orientado a columnas que se caracteriza por la adyacencia de datos secuenciales, el acceso aleatorio en tiempo constante, el patrón de programa Single Instruction Multiple Data y la relocalización de datos con punteros sin uso de copias. Todo esto al final se traduce en tiempos más rápidos de ingesta, manipulación, transformación y exportación de datos. (Apache Arrow Documentation, 2020)
Sin embargo, tal vez la mayor ventaja de Apache Arrow no sea su capacidad de mejorar el rendimiento de herramientas ya existentes, sino su capacidad práctica de unificar el ecosistema de ciencias de datos. Esto se debe a la gran popularidad de diversas implementaciones del modelo de datos basado en tablas o dataframes. Ésta es una estructura de datos muy común y se pueden encontrar implementaciones en múltiples languajes como Python, Scala y R, así como en múltiples herramientas como Apache Spark, Pandas y Dask.
En general, si bien los dataframes representan el mismo tipo de datos, sus implementaciones pueden variar sobremanera. Es por esto que la conversión de datos entre un formato y el otro requiere la creación de una herramienta específica y las más de las veces esto implica un proceso de copia y conversión (Ilustración 3) que en total se caracteriza por una complejidad lineal sobre los datos.
Sin embargo, si todos estas implementaciones siguieran el mismo formato a bajo nivel, sería posible simplemente mover apuntadores para poder pasar entre un formato y otro (Ilustración 4). En efecto, esto es lo que hace precisamente Apache Arrow. (Sitio Web de Apache Arrow, 2020)
Ilustración 3: antes de Arrow, un método que copia y convierte ha de hacerse por cada par de formatos basados en columnas (fuente: https://arrow.apache.org/)
Ilustración 4: con Arrow, cada formato basado en columnas sólo ha de seguir el estándar de Arrow (fuente: https://arrow.apache.org/)
Si bien Apache Arrow ayuda sobremanera a mitigar el problema del bajo rendimiento durante la ingesta y exportación de datos, así como a mejorar la interoperabilidad entre distintos proyectos, aún se puede mejorar mucho desde el punto de vista de la concurrencia y paralelización de operaciones. Por esta razón, nace el proyecto cuDF, de RAPIDS (Ilustración 5).
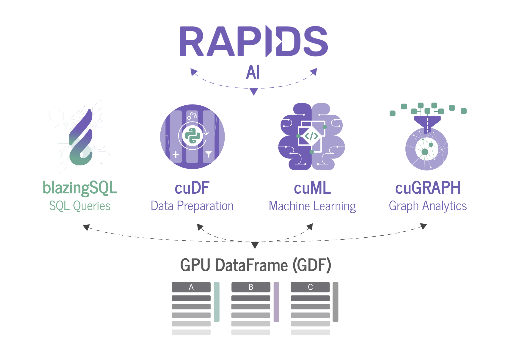
Ilustración 5: relación entre los componentes del ecosistema de RAPIDS (fuente: https://github.com/BlazingDB/blazingsql)
Qué es RAPIDS
En efecto, RAPIDS es una organización que ofrece un conjunto de herramientas de código abierto que permiten ejecutar proyectos de ciencias de datos y analítica usando GPU de principio a fin teniendo como base a CUDA y también da soporte a despliegues distribuidos con múltiples GPU. (RAPIDS, 2020)
Por su parte, cuDF es la principal implementación de un dataframe basado en Apache Arrow y adaptado completamente para ejecutar operaciones de carga, unión, agregación, filtrado y manipulación de datos usando siempre GPU. Como es un dataframe, la principal ventaja que ofrece cuDF es un API bien conocido por los usuarios de herramientas como Apache Spark y Pandas mientras ofrece operaciones aceleradas por GPU. Es decir, es la combinación perfecta entre Pandas y CUDA, sin las limitaciones del primero y sin los detalles de bajo nivel del segundo. (RAPIDS, cuDF GitHub Repository, 2020)
Si bien Apache Arrow les permite a los dataframes basados en memoria principal el poder interoperar, también les permite lo mismo a los dataframes basados en memoria del GPU. Sin embargo, aquí surge un cuello de botella: el ancho de banda del bus de memoria del GPU (Barlas, 2015, págs. 391, 392). Esto implica que la transmisión de datos entre memoria principal y el GPU ha de limitarse necesariamente a la entrada de datos y el retorno de los resultados, todo mientras se dejan los datos la mayor parte del tiempo en el GPU conforme son manipulados.
Aunque la principal intención del proyecto cuDF es la introducción de un dataframe con API bien conocido y parecido al encontrado en Pandas, el uso del GPU tras bambalinas exige un nuevo tipo de disciplina. Sin embargo, para poder entender esto, es menester comprender a CUDA.
Qué es CUDA
CUDA, o Compute Unified Device Architecture, es una arquitectura introducida por Nvidia en 2006 y es la piedra fundacional de muchos API y bibliotecas de nivel más alto que explotan el poder de cómputo de los GPU. El modelo de programación seguido por CUDA sigue el patrón GSLP (globally sequential, locally parallel). Para poder implementar este patrón, CUDA despliega todos los hilos que puede como un grupo y aplica una misma función a todos ellos mientras varía los argumentos de ésta dependiendo del hilo. Esta función es mejor conocida como el kernel. (Barlas, 2015, págs. 393, 394)
Si usaramos CUDA directamente, el kernel se vería como en la Ilustración 6:

Ilustración 6: Ejemplo de kernel en CUDA (Barlas, 2015, pág. 411)
Es decir, el kernel es una función complicada, pues se aplica a todos los hilos y es responsabilidad de esta determinar, de ser necesario, en cuál hilo está y con qué subconjunto de los datos está operando. En este ejemplo, el identificador del hilo es usado para obtener los datos apropiados de la memoria del GPU.
Por suerte, para nosotros todos estos detalles permanecen ocultos si usamos cuDF:
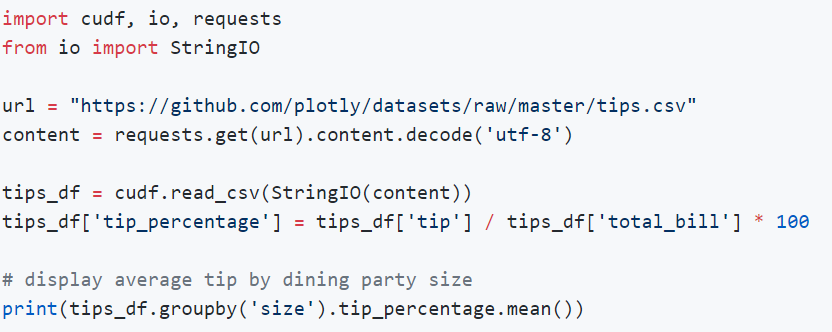
Ilustración 7: ejemplo del API de cuDF (fuente: https://github.com/rapidsai/cudf)
En la Ilustración 7 se puede ver cómo unas pocas líneas de código con cuDF son equivalentes a la ingesta de datos, transmisión de datos entre memoria principal y GPU, el uso de varios kernels y el retorno de resultados a memoria principal en CUDA.
Sin embargo, no todo es color de rosas. Existen casos en los que resulta imprescindible bajar de nivel en cuDF y usar el concepto de kernel. Esto ocurre especialmente cuando el usuario ha de implementar funciones personalizadas, mejor conocidas como UDF o user defined functions. Un ejemplo de ello se puede apreciar en la Ilustración 8:
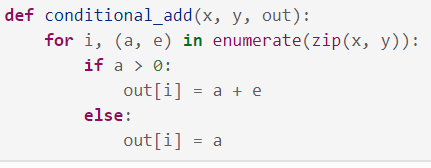
Ilustración 8: ejemplo de kernel en cuDF con UDF (fuente: https://docs.rapids.ai/api/cudf/stable/guide-to-udfs.html#DataFrame-UDFs)
Hemos visto que con cuDF se pueden aprovechar las ventajas de los GPU, pero resulta importante determinar cuándo es apropiado usar estas herramientas. Mientras los núcleos de un CPU son poderosos y son adecuados para procesar tareas complicadas e intensivas en cómputo, los núcleos de un GPU son perfectos para procesar numerosas tareas simples. Esto se refleja en el bajo número de núcleos que tiene un CPU en contraste con el gran número de los que dispone un GPU. (OMNISCI, 2020)
Ahora bien, hemos visto todas las ventajas de Apache Arrow y los dataframes acelerados por GPU, pero también surge la inquietud de cuánto del proceso ETL se puede mejorar gracias a estas herramientas. La respuesta es: todo. Un ejemplo de ello es el surgimiento de motores de SQL acelerados por GPU, como BlazingSQL. Ésta herramienta fue construida sobre el cuDF y es interoperable con diversos formatos de dataframe gracias a su uso de Apache Arrow. (BlazingSQL Documentation, 2020)
Un ejemplo de cuán fácil resulta usar BlazingSQL con cuDF lo podemos ver en la Ilustración 9, donde se crea un contexto de trabajo. Esto resulta similar a cómo se trabaja con Apache Spark.

Ilustración 9: creación de un contexto con BlazingSQL (BlazingSQL, 2020)
Luego de eso, se puede usar cuDF para cargar datos y crear una tabla en BlazingSQL (Ilustración 10). Otra vez, esto resulta similar a Apache Spark cuando se desea crear una tabla con Hive.

Ilustración 10: creación de una tabla en BlazingSQL (BlazingSQL, 2020)
Finalmente, se pueden ejecutar consultas con SQL:
Ilustración 11: consulta de SQL con BlazingSQL (BlazingSQL, 2020)
BlazingSQL no está solo, pues existen otras bases de datos cuyo propósito es acelerar operaciones básicas usando GPU. Un ejemplo de ello es OmniSciDB, un motor de SQL que ofrece operaciones de analítica aceleradas por GPU. Su arquitectura está basada en la conjunción de tres capas que se concentran en el uso de recursos del GPU, CPU y SSD (Ilustración 12).
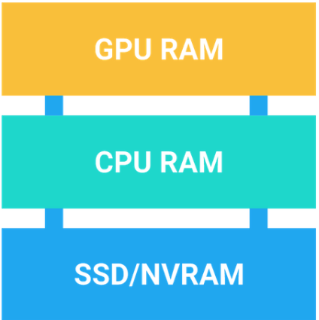
Ilustración 12: capas de memoria y cómputo de OMNISCI (fuente: https://www.omnisci.com/platform/omniscidb)
Una característica importante de este motor es su modelo híbrido de cómputo, pues en todo momento trata de ejecutar al mismo tiempo operaciones distintas tanto en CPU como en GPU. Adicionalmente, también se permite la escalabilidad horizonal de alta disponibilidad, pues ofrece un modelo de memoria de tipo shared-nothing entre distintos GPU: cada vez que más de un nodo es usado, cada uno sólo tiene acceso a un subconjunto de los datos. Los datos al final del cómputo son recogidos por el CPU. Finalmente, promote tener a futuro una excelente interoperabilidad con herramientas como TensorFlow y PyTorch debido al soporte de Apache Arrow. (OMNISCI, 2020)
Ilustración 13: ejemplo de reporte acelerado por GPU de OMNISCI (fuente: https://www.omnisci.com/demos/ships)
Un ejemplo de cuán poderosa puede ser la aceleración por GPU en los problemas de analítica es el benchmark hecho por el consultor Mark Litwintschik en el año 2017 en el que determina el tiempo que le toma a BrytlytDB ejecutar consultas comunes, siendo esta una base de datos similar a OmniSciDB, pero privada. Para su experimento descargó 50 GB de datos sobre carreras de taxi y los cargó sobre esta base de datos. Como resultado obtuvo tiempos de ejecución que no tomaban más de un segundo para diversas tareas de agrupación. (Litwintschik, 2020)
En respuesta al reporte de Litwintschik, Richard Heyns de Brytlyt, decidió comparar esta base de datos con Apache Spark. A pesar del costo superior de usar GPU, el tiempo de cómputo fue tan corto que resultó ser mucho más barato que mantener un clúster de Apache Spark:

Ilustración 14: comparación entre Apache Spark y BrytlytDB (fuente: https://www.brytlyt.com/blog/apache-spark-and-brytlyt/)
En definitiva, más allá de Pandas existen herramientas que permiten afrontar los cuellos de botella que típicamente encontramos durante las tareas de análisis y procesamiento de datos. Desde problemas de serialización y cambio de formato, hasta el uso de algoritmos paralelos, todo se ha venido resolviendo con el surgir de nuevos proyectos y cambios de paradigma. Si bien esto exige un dominio mucho más amplio de las herramientas que ofrece el área del cómputo de alto desempeño, todo esto se hace necesario a medida que se va redefiniendo qué significa ser un ingeniero de datos.
Si desean más información sobre estas herramientas recomiendo ver estos vídeos:
- Wes McKinney – Apache Arrow: Leveling Up the Data Science Stack
- Supercharging Analytics with GPUs: OmniSci/cuDF vs Postgres/Pandas/PDAL – Masood Krohy
- Accelerating Tensorflow with Apache Arrow on Spark (Holden Karau)
- End to End Data Science Without Leaving The GPU – Randy Zwitch
Si quieres conocer más de cerca nuestro área de Data & Analytics de Hiberus, no dudes en contactar con nosotros. ¡Estaremos encantados de ayudarte!
¿Quieres más información sobre nuestros servicios de Data & Analytics?
Contacta con nuestro equipo de expertos en Data & Analytics
