1. Introduction to LLM Fine-Tuning
Fine-tuning is the process of adapting a pre-trained Large Language Model (LLM) to perform specific tasks or operate in particular domains. It leverages transfer learning, allowing the model to benefit from knowledge gained during pre-training while adapting to new, often more specialized, tasks.
Benefits of Fine-Tuning:
- Improved performance on specific tasks
- Reduced data requirements compared to training from scratch
- Faster training times
- Ability to adapt state-of-the-art models to custom use cases
2. LLM Architectures
Understanding the underlying architecture of LLMs is crucial for effective fine-tuning. Most modern LLMs are based on the Transformer architecture.
Transformer Architecture
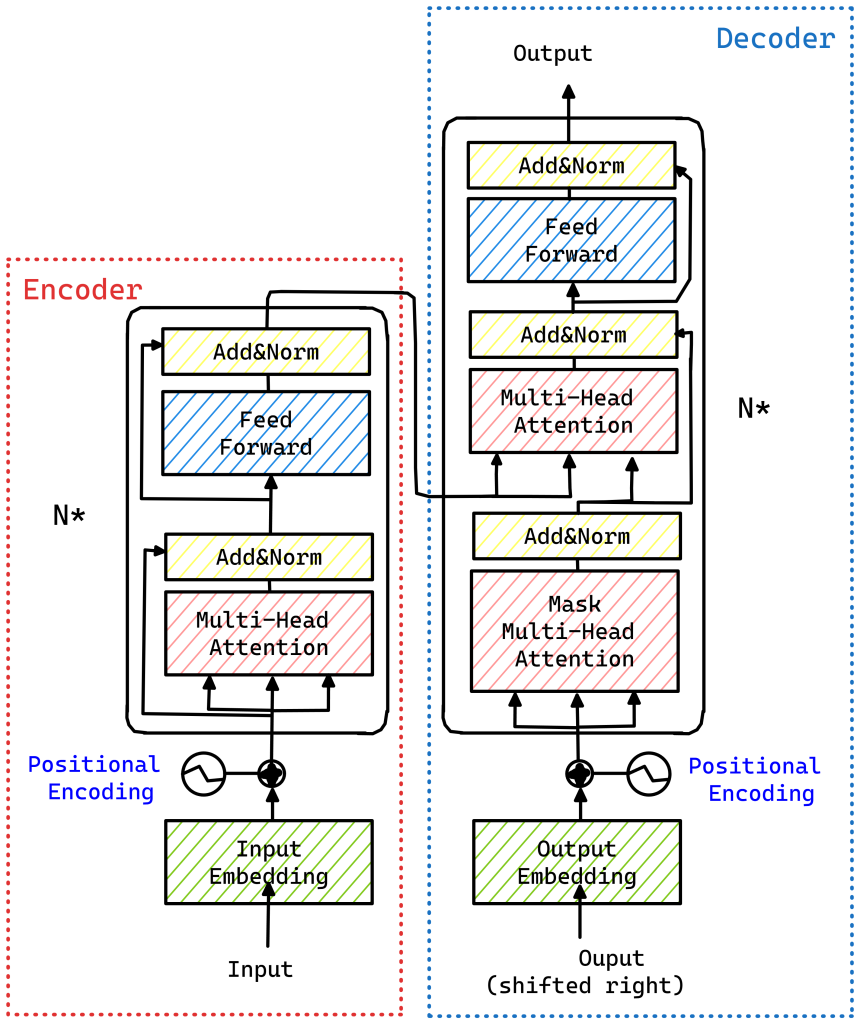
The Transformer architecture, introduced in the paper “Attention Is All You Need,” forms the backbone of modern LLMs. It consists of several key components:
- Encoder-Decoder structure
- Encoder: Processes the input sequence
- Decoder: Generates the output sequence
- Self-attention mechanisms: Allow the model to weigh the importance of different words in the input when processing each word.
- Positional encodings: Provide information about the position of words in the sequence, as the self-attention mechanism itself is position-agnostic.
- Layer normalization: Normalizes the inputs to each sub-layer to stabilize the learning process.
- Residual connections: Allow for better gradient flow through the network.
Key components that are often the focus of fine-tuning:
- Attention layers
- Feed-forward neural networks
- Embedding layers
2.1 Encoder-Only Architecture
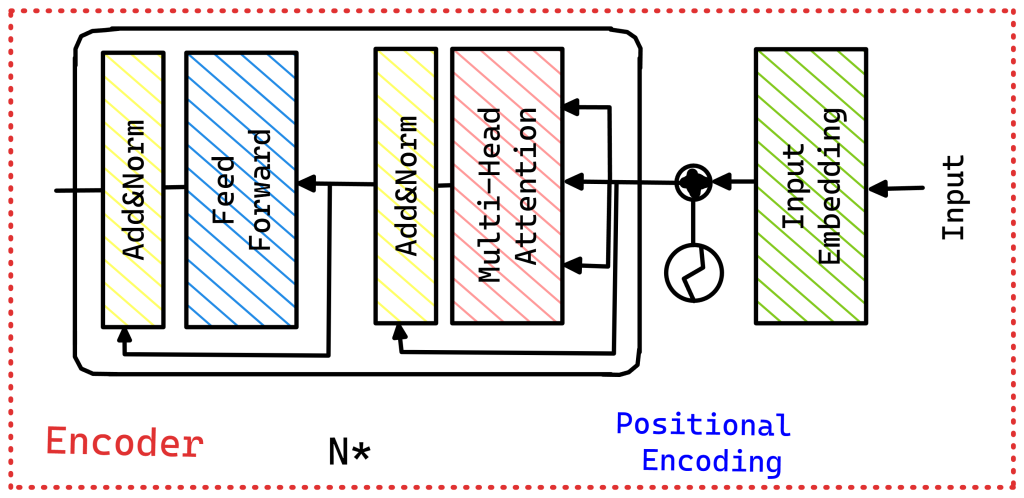
Encoder-only models, such as BERT (Bidirectional Encoder Representations from Transformers), process input text bidirectionally. They are particularly well-suited for tasks that require understanding of the entire input context.
Key features:
- Bidirectional attention
- Masked language modeling pre-training
- Suitable for tasks like classification, named entity recognition, and question answering
Fine-tuning approach: When fine-tuning encoder-only models, typically a task-specific head (e.g., a classification layer) is added on top of the encoder outputs. The entire model, including the encoder layers, is then fine-tuned on the target task.
2.2 Decoder-Only Architecture
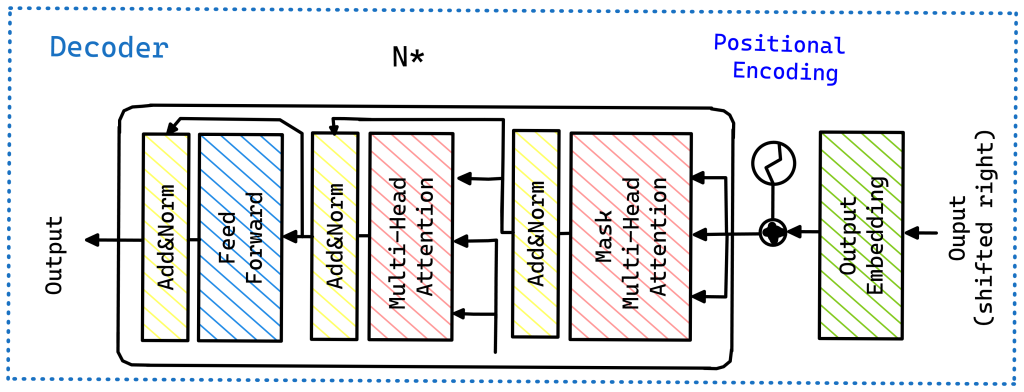
Decoder-only models, like GPT (Generative Pre-trained Transformer), process input sequentially and are auto-regressive, meaning they predict the next token based on all previous tokens.
Key features: – Unidirectional (left-to-right) attention – Causal language modeling pre-training – Suitable for tasks like text generation, completion, and some classification tasks
Fine-tuning approach: Fine-tuning decoder-only models often involves continued pre-training on domain-specific data, followed by fine-tuning on the target task. For tasks like classification, a special token or prompt is typically used to guide the model’s output.
2.3 Encoder vs Decoder in Fine-Tuning
When fine-tuning LLMs, the approach can differ based on whether the model is encoder-based, decoder-based, or uses both components:
- Encoder-only models (e.g., BERT)
- Typically used for tasks that require understanding of the input, such as classification or named entity recognition.
- Fine-tuning often involves adding a task-specific head (e.g., a classification layer) on top of the encoder outputs.
- Example: Fine-tuning BERT for sentiment analysis by adding a classification layer to the [CLS] token output.
- Decoder-only models (e.g., GPT family)
- Used for generative tasks where the model needs to produce text.
- Fine-tuning often involves training the model to generate specific types of text or follow certain patterns.
- Example: Fine-tuning GPT-3 to generate legal documents by training on a dataset of legal texts.
- Encoder-Decoder models (e.g., T5)
- Versatile models that can be used for both understanding and generation tasks.
- Fine-tuning can involve adapting both the encoder and decoder for tasks like translation or summarization.
- Example: Fine-tuning T5 for text summarization by training it to encode long articles and decode them into concise summaries.
3. Fine-Tuning Approaches
3.1 Full Fine-Tuning
Full fine-tuning involves updating all parameters of the pre-trained model. This approach can achieve the best performance but is computationally expensive and requires significant GPU/TPU resources.
3.2 Parameter-Efficient Fine-Tuning (PEFT)
PEFT methods aim to update only a small subset of model parameters, reducing computational requirements and mitigating catastrophic forgetting.
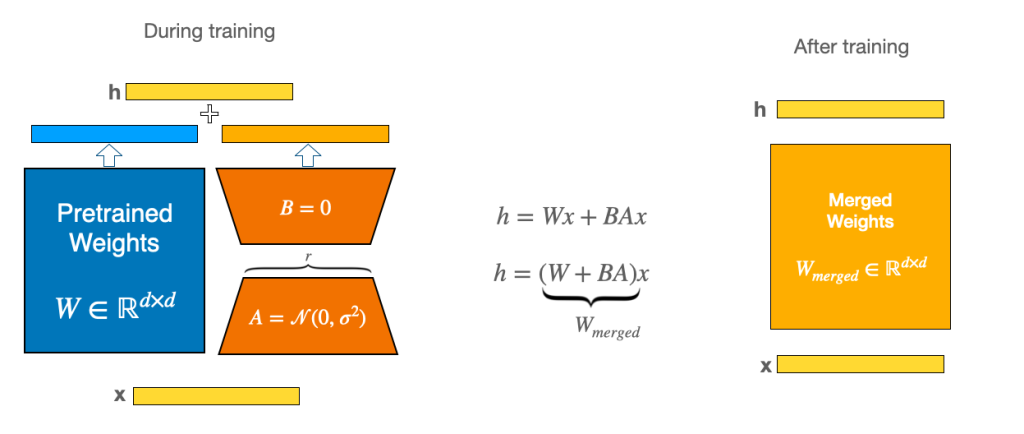
Low-Rank Adaptation (LoRA)
LoRA adds small trainable “rank decomposition” matrices to the attention layers. This dramatically reduces the number of trainable parameters while still allowing the model to adapt to new tasks.
Key concept: Rank decomposition LoRA decomposes the weight updates into the product of two low-rank matrices, enabling efficient fine-tuning with fewer parameters.
Adapters
Adapters are small trainable modules inserted into the model architecture. They allow the model to adapt to new tasks while keeping most of the pre-trained weights frozen.
Key concept: Bottleneck architecture Adapters typically use a bottleneck architecture, where the input is projected to a lower dimension, transformed, and then projected back to the original dimension.
Prefix Tuning
Prefix tuning involves optimizing a sequence of continuous task-specific vectors (the “prefix”) that are prepended to the input. This allows the model to adapt to new tasks without changing the original model parameters.
Key concept: Continuous prompts Unlike discrete text prompts, prefix tuning uses learned vector representations that can capture task-specific information in a more flexible way.
3.3 QLoRA (Quantized LoRA)
QLoRA combines quantization with LoRA, allowing for efficient fine-tuning of large models on consumer-grade hardware.
Key concept: Mixed-precision training QLoRA uses a mix of low-precision (e.g., 4-bit) weights for the main model and higher-precision (e.g., 16-bit) weights for the LoRA parameters, balancing efficiency and performance.
4. Advanced Concepts in LLM Fine-Tuning
Flash Attention
Flash Attention is an optimization technique that significantly improves the efficiency of attention computations in Transformer models. Key aspects of Flash Attention include:
- Memory efficiency: Flash Attention reduces memory usage by avoiding the storage of large attention matrices.
- Computational speed: It accelerates attention computations, particularly for long sequences.
- Scalability: Flash Attention allows for processing of longer sequences than traditional attention mechanisms.
- Integration with fine-tuning: When fine-tuning models that incorporate Flash Attention, it’s important to ensure that the fine-tuning process is compatible with this optimized attention mechanism.
Positional Encodings
Positional encodings provide information about the position of tokens in the sequence. During fine-tuning, these are typically kept fixed, but some approaches may involve learning task-specific position embeddings.
Layer Normalization
Layer normalization helps stabilize the activations in deep neural networks. In the context of fine-tuning, adapting or re-learning the layer normalization parameters can be beneficial for task-specific performance.
Mixture of Experts (MoE)
Mixture of Experts is an architecture where multiple “expert” neural networks specialize in different aspects of the task. In the context of LLMs:
- Structure: An MoE layer consists of multiple feed-forward networks (experts) and a gating network that decides which experts to use for each input.
- Efficiency: MoE allows for increasing model capacity without a proportional increase in computation, as only a subset of experts is active for each input.
- Fine-tuning considerations: When fine-tuning MoE models, special care must be taken to balance the usage of different experts and potentially adapt the gating mechanism.
5. Fine-Tuning Approaches by Task
5.1 Task-Specific Fine-Tuning
Adapts the model to particular NLP tasks such as text classification, named entity recognition, or question answering.
5.2 Domain-Specific Fine-Tuning
Tailors the model to a specific field or industry, such as legal, medical, or financial domains.
5.3 Instruction Tuning
Improves the model’s ability to follow instructions and perform diverse tasks based on natural language prompts.
6. Key Parameters and Hyperparameters
- Learning rate: The step size at each iteration while moving toward a minimum of the loss function.
- Batch size: The number of training examples used in one iteration.
- Number of epochs: The number of complete passes through the training dataset.
- LoRA rank: In LoRA, the dimension of the low-rank matrices.
- Adapter size: In adapter-based fine-tuning, the dimension of the adapter layers.
- Prefix length: For prefix tuning, the number of trainable tokens prepended to the input.
7. Popular Models for Fine-Tuning
Various models are suitable for fine-tuning, including open-source options like LLaMA, BLOOM, and T5, as well as commercial models like GPT-3 and PaLM.
Encoder-Only Models (e.g., BERT)
- Often fine-tuned by adding a task-specific head (e.g., classification layer)
- May require careful handling of special tokens (e.g., [CLS] token for classification)
- Bidirectional nature makes them suitable for tasks requiring full context understanding
Decoder-Only Models (e.g., GPT)
- Often fine-tuned using causal language modeling objectives
- May require careful prompt engineering to guide the model’s output
- Sequential nature makes them particularly suitable for generative tasks
Encoder-Decoder Models (e.g., T5)
- Can be fine-tuned on a wide variety of tasks by framing them as text-to-text problems
- May require careful design of input and output formats
- Flexibility allows for creative task formulations
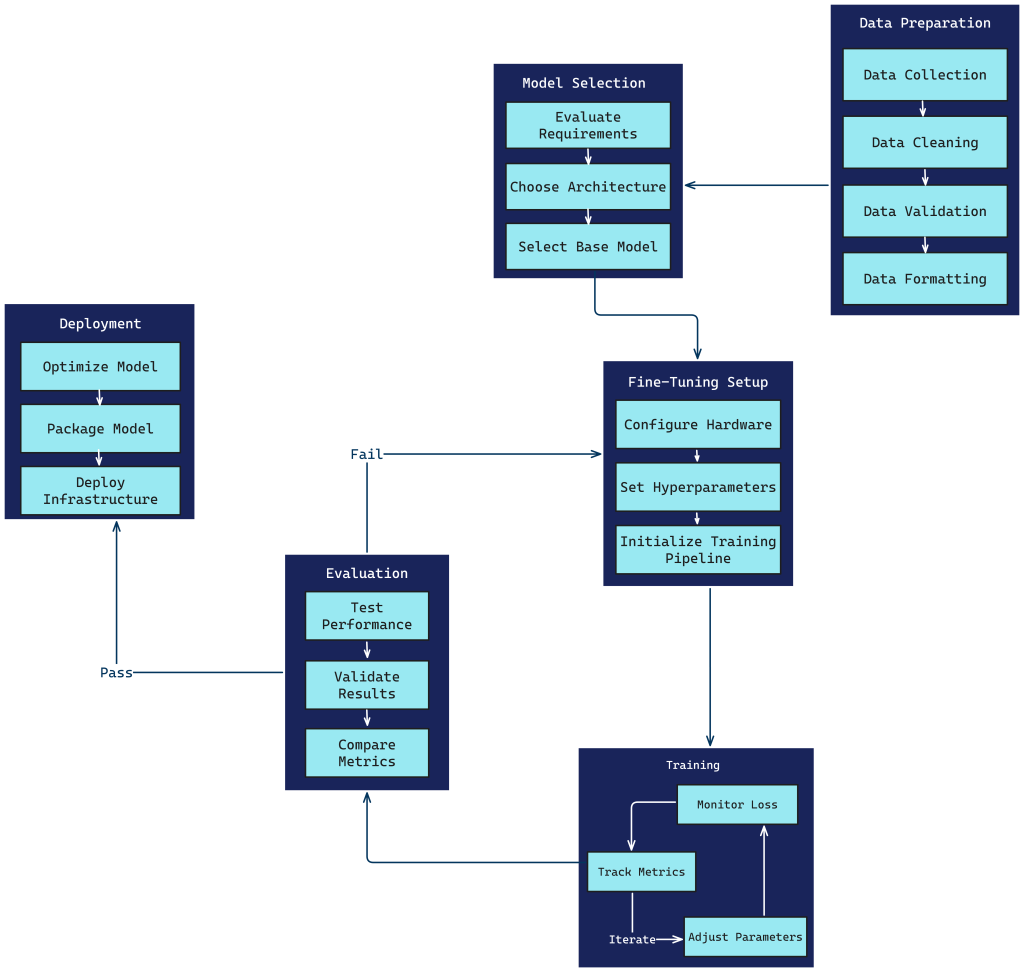
8. Fine-Tuning Process
The fine-tuning process typically involves:
- Data Preparation
- Model Selection
- Fine-Tuning Setup
- Training
- Evaluation
- Deployment
Each step requires careful consideration of the specific task, available resources, and desired outcomes.
9. Challenges and Limitations of LLM Fine-Tuning
While LLM fine-tuning offers numerous benefits, it also comes with several challenges and limitations:
- Overfitting: Fine-tuned models can easily overfit to small datasets, leading to poor generalization on new data. Careful monitoring and techniques like early stopping are crucial.
- Computational Resources: Fine-tuning large models requires significant computational power, often necessitating expensive GPU or TPU hardware.
- Data Quality and Quantity: The performance of fine-tuned models heavily depends on the quality and quantity of the fine-tuning data. Acquiring high-quality, task-specific data can be challenging and time-consuming.
- Catastrophic Forgetting: Models may lose their general capabilities when fine-tuned on specific tasks, a phenomenon known as catastrophic forgetting.
- Ethical Considerations: Fine-tuned models can potentially amplify biases present in the training data or be misused for generating harmful content.
- Evaluation Complexity: Assessing the performance of fine-tuned models, especially for open-ended tasks, can be challenging and often requires careful design of evaluation metrics.
- Reproducibility: Due to the stochastic nature of training and the complexity of large models, reproducing fine-tuning results can be difficult.
- Licensing and Legal Issues: Using pre-trained models for fine-tuning may involve navigating complex licensing terms and potential legal challenges.
- Model Drift: Fine-tuned models may become less effective over time as the target domain evolves, necessitating periodic re-tuning or updating.
10. Cloud Platforms for LLM Fine-Tuning
Cloud platforms play a crucial role in making LLM fine-tuning accessible and scalable. They offer powerful hardware, optimized software stacks, and managed services that can significantly enhance the fine-tuning process. Here’s an overview of major cloud platforms and their offerings for LLM fine-tuning:
1. Amazon Web Services (AWS)
- SageMaker: AWS’s machine learning platform offers tools specifically designed for LLM fine-tuning.
- EC2 Instances: Provides a range of GPU-enabled instances, including the powerful P4 instances with NVIDIA A100 GPUs.
- Distributed Training: Supports distributed training across multiple GPUs and machines.
- Key Features: Managed Spot Training for cost optimization, Elastic Inference for flexible inference deployment.
2. Google Cloud Platform (GCP)
- Vertex AI: Google’s unified ML platform that supports end-to-end LLM workflows.
- TPU Pods: Offers access to Google’s custom Tensor Processing Units (TPUs), which can be particularly effective for certain LLM architectures.
- Google Kubernetes Engine (GKE): Allows for scalable, container-based fine-tuning setups.
- Key Features: AutoML for automated fine-tuning, AI Platform Prediction for serving fine-tuned models.
3. Microsoft Azure
- Azure Machine Learning: Provides a comprehensive environment for training, deploying, and managing LLMs.
- NC and ND-series VMs: Offers NVIDIA GPU-enabled virtual machines optimized for deep learning.
- Azure Databricks: Supports distributed fine-tuning on Apache Spark clusters.
- Key Features: Azure Cognitive Services for pre-built AI models, Azure Kubernetes Service for scalable deployments.
4. IBM Cloud
- Watson Machine Learning: Offers tools for training and deploying LLMs.
- GPU-enabled virtual servers: Provides access to NVIDIA GPU instances.
- Key Features: Watson Studio for collaborative ML workflows, Cloud Pak for Data for end-to-end data and AI platform.
Do you want to harness the power of Generative AI to boost your business? We have a team of experts in Generative AI and Data who have developed GenIA Ecosystem, an ecosystem of proprietary conversational AI, content and data generation solutions adapted to the needs of each market and client. Contact us and we will be happy to help you.
Contact with our GenIA teamWant to learn more about our Artificial Intelligence services?

What’s up, I read your new stuff daily. Your writing style is witty, keep doing what you’re doing!
I like looking through an article that will make people think.